
【论文标题】Harms of Gender Exclusivity and Challenges in Non-Binary Representation in Language Technologies
【作者团队】Sunipa Dev, Masoud Monajatipoor, Anaelia Ovalle, Arjun Subramonian, Jeff M Phillips, Kai-Wei Chang
【发表时间】2021/08/27
【机 构】UCLA、犹他大学
【论文链接】https://arxiv.org/abs/2108.12084v1
【推荐理由】蛋白结构表征的基于注意力提取方式
在语言任务的背景下,以及在审查语言模型所传播的陈规定型观念时,性别问题被广泛讨论。然而,目前的讨论主要是将性别视为二进制,这可能会延续一些伤害,如对非二进制性别身份的循环抹杀。这些伤害是由模型和数据集的偏见驱动的,这些偏见是社会对非二元性别不承认和缺乏理解的后果。本文解释了性别和围绕它的语言的复杂性,并对非二进制人士进行了调查,以了解与英语语言技术中对性别的二元处理有关的伤害。本文还详细介绍了目前的语言表征,如GloVe、BERT,是如何捕捉和延续这些伤害的,以及为使表述公平地编码性别信息而需要承认和解决的相关挑战。
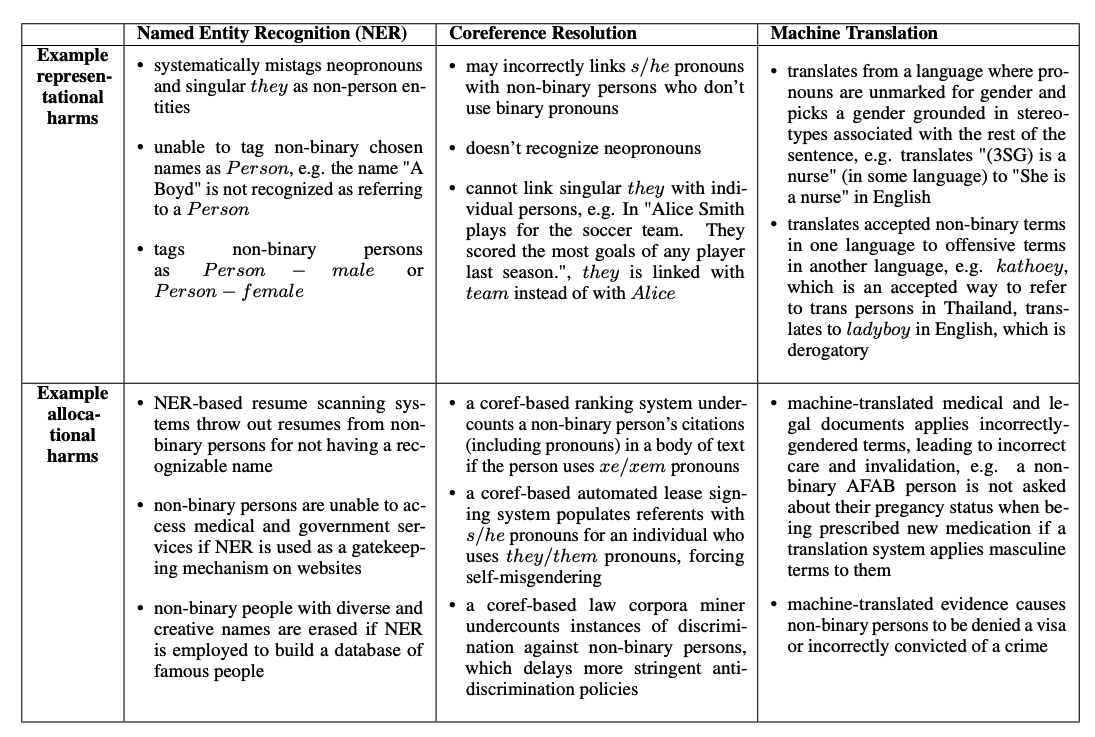
上图展示了三种常见的NLP任务(命名实体识别(NER)、核心关系解析和机器翻译)。这些domo伴随着关于非二元群体可能因这些任务而面临的潜在代表性和分配性伤害的非引导性问题。这些问题的措辞是有意问及可能发生的伤害,而不是暗示可能发生的伤害。可以看到,在所有三项任务中,对人的误认是一个共同的问题。本文发现,对于所有的任务,84%以上的受访者可以看到/想到非二元性别的不良结果。此外,在调查对象看来,危害的严重性在机器翻译中是最高的,这也是广大民众更常用的一项任务。
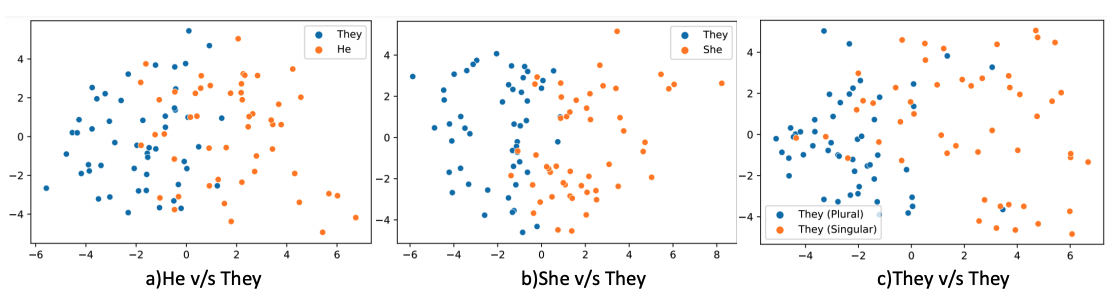
上图展示了BERT表征在性别划分上的差别。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢