
【标题】GST: Group-Sparse Training for Accelerating Deep Reinforcement Learning
【作者团队】Juhyoung Lee, Sangyeob Kim, Sangjin Kim, Wooyoung Jo, Hoi-Jun Yoo
【论文链接】https://arxiv.org/pdf/2101.09650.pdf
【发表日期】2021.1.24
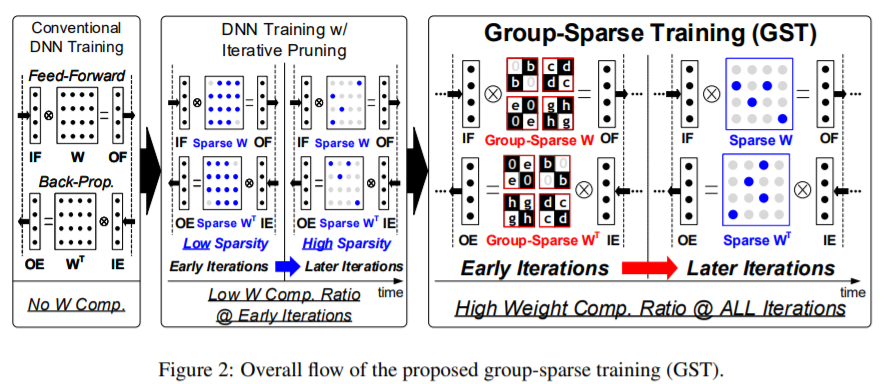
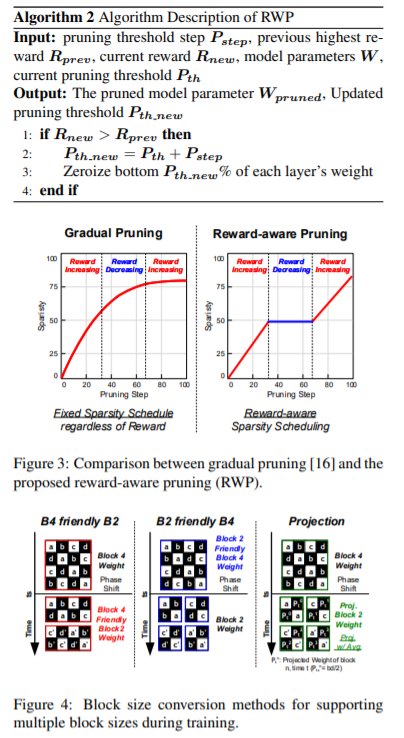
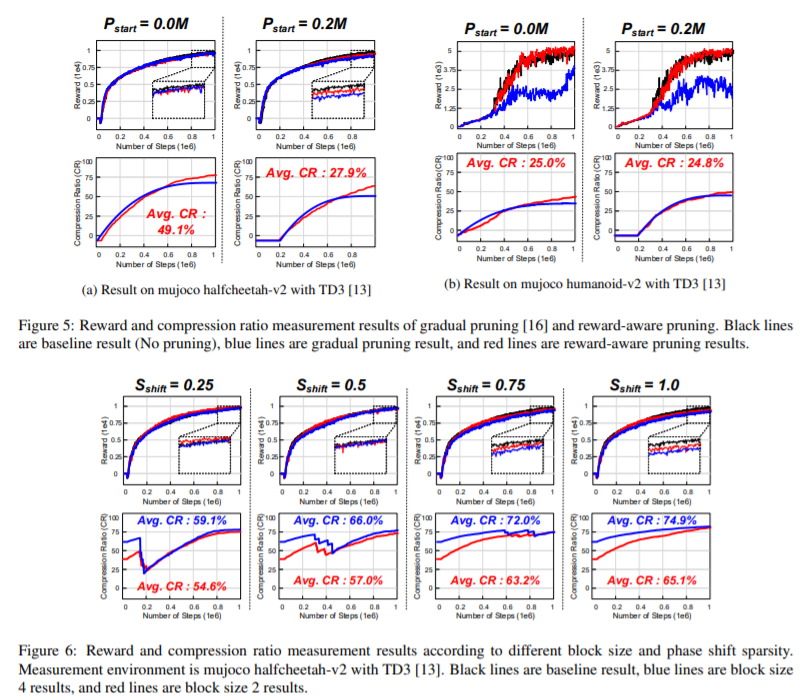
【推荐理由】深度强化学习(DRL)在顺序决策问题上取得了显著的成功,但要获得如此好的学习效果需要较长的训练时间。为了解决这个问题,诸多研究学者已经提出了许多并行和分布式DRL训练方法,但很难在资源有限的设备上利用它们。为了加速真实边缘设备中的DRL,必须解决由于大重量事务而导致的内存带宽瓶颈。然而,先前的迭代剪枝不仅在训练开始时表现出较低的压缩率,而且使得 DRL 训练不稳定。为了克服这些缺点,本文提出了一种新颖的DRL训练加速权值压缩方法,称为群稀疏训练(GST)。GST选择性地利用块循环压缩,在DRL训练的所有迭代过程中保持较高的权重压缩比,并通过奖励感知修剪动态自适应目标稀疏性,以实现稳定训练。由于这些功能,GST实现了25 \%p∼在 TD3 训练的 Mujoco Halfcheetah-v2 和 Mujoco humanoid-v2 环境中,平均压缩率比没有奖励下降的迭代修剪方法高 41.5 \%p。


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢