标题:谷歌|The Power of Scale for Parameter-Efficient Prompt Tuning(具有规模能力的参数高效提示优化)
https://arxiv.org/pdf/2104.08691v2.pdf
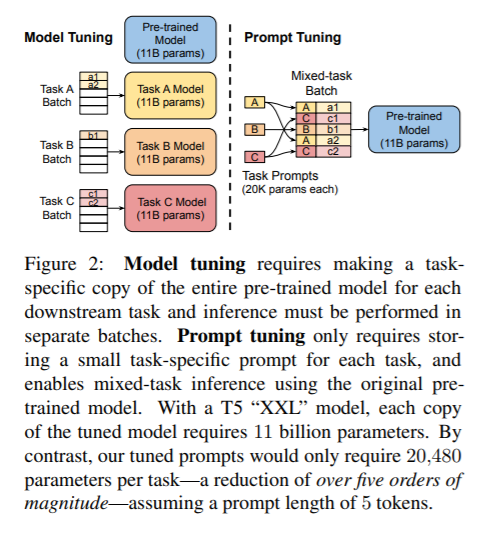
内容中包含的图片若涉及版权问题,请及时与我们联系删除

标题:谷歌|The Power of Scale for Parameter-Efficient Prompt Tuning(具有规模能力的参数高效提示优化)
https://arxiv.org/pdf/2104.08691v2.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除
沙发等你来抢

评论
沙发等你来抢