
1. 【NeurIPS 2020】Learning to Dispatch for Job Shop Scheduling via Deep Reinforcement Learning
链接:https://arxiv.org/abs/2010.12367
作者:Cong Zhang, Wen Song, Zhiguang Cao, Jie Zhang, Puay Siew Tan, Chi Xu
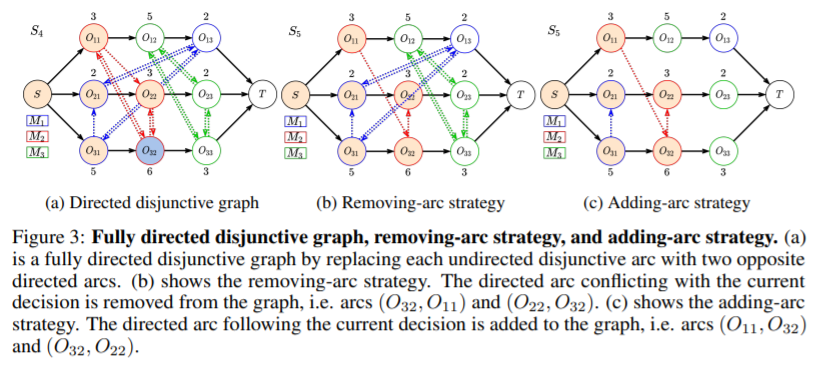
导读:优先调度规则(PDR)被广泛用于解决现实世界的作业车间调度问题(JSSP), 但设计有效 PDR 是一项繁琐的任务,需要大量的专业知识,而且通常只能适用有限的场景。 在本文中,作者提出了基于深度强化学习Agent自动端到端学习 PDR。模型利用 JSSP 的析取图表示来适应图神经网络,将state输入至神经网络端到端输出action。实验表明,Agent能够学习到高质量 PDR,并且具有良好的泛化性。
2.【SOCS 2021】SOLO: Search Online, Learn Offline for Combinatorial Optimization Problems
链接:https://arxiv.org/abs/2104.01646
作者:Joel Oren, Chana Ross, Maksym Lefarov, Felix Richter, Ayal Taitler, Zohar Feldman, Christian Daniel, Dotan Di Castro
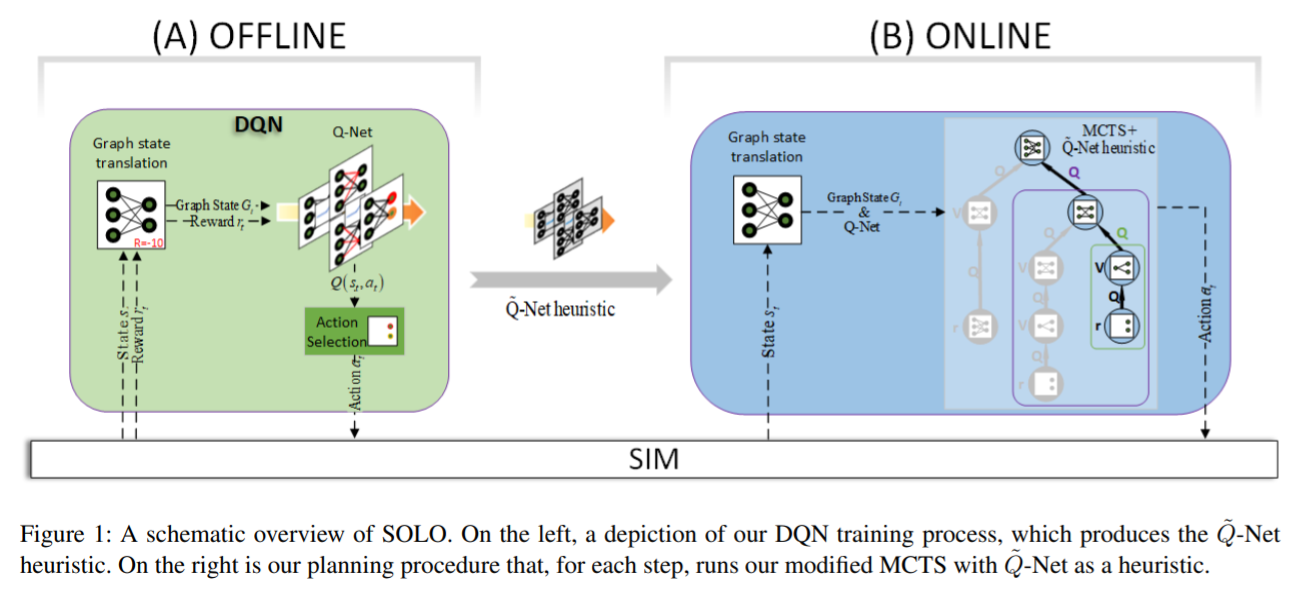
导读:文章由Bosch Center for AI和以色列理工学院的学者完成。在本文中,作者提出了一种GNN-based端到端求解CO的模型。为了提高在线搜索的质量和效率,SOLO模型还采用MCTS来进行离线学习。实验结果表明,关于并行机作业调度问题(PMSP)和容量约束车辆路径问题(CVRP),SOLO与现有的基于学习的方法和启发式方法相比可以找到更高质量的解。
3.【NeurIPS 2019】Learning to Perform Local Rewriting for Combinatorial Optimization
链接:https://arxiv.org/abs/1810.00337
作者:Xinyun Chen, Yuandong Tian
导读:本文由来自UC Berkeley和Facebook AI Research的学者完成。基于搜索的组合优化方法通常以启发式方法为指导,然而设计出好的启发式往往是困难和耗时的。在本文中,作者提出一个基于深度强化学习的组合优化问题搜索模型NeuRewriter,学习一个策略选择启发式和重写当前解的局部分量来迭代改进它,直到收敛。该策略分解为区域选择和规则选择组件,每个参数由一个神经网络进行训练,并使用Actor-Critic进行训练。Neurewriter 在表达式简化、在线作业调度和车辆路径问题这任务中性能优于Baseline算法。

编辑人:邓兴超 刘长安 王天富
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢