
今天的分享主要关注图神经网络架构方面的工作,相关内容包括:
【WWW 2019】Heterogeneous graph attention network
作者:Xiao Wang, Houye Ji, Chuan Shi, Bai Wang
文章地址:https://arxiv.org/pdf/1903.07293.pdf
导读:论文针对异构图的基于 meta-path 的 node embedding 学习问题,解决之前的模型:(1)只考虑单个 meta-path 的局限;(2)没有考虑不同 meta-path 的权重这两方面的问题。在该论文中,作者提出了一种两层 注意力机制:节点级别的注意力(Node-level attention):考虑邻居对当前节点的重要性。为使模型更加稳定,采用了多头注意力机制,将节点表示为一个合并了K头的嵌入表示;语义级别的注意力(Semantic-level attention):对于节点 i, 为每种 meta-path 学习一个合并了的 K head embedding。然后,通过计算每个 meta-path 的重要性,最后以重要性为权重线性组合这些 embedding ,通过全连接层得到了用于表达节点 i 的embedding。论文中的Baseline方法包括:GCN、GAT、HAN of Node、HAN of Semantic、HAN。从节点分类、聚类的实验结果来看:HAN基本上都是最优的。
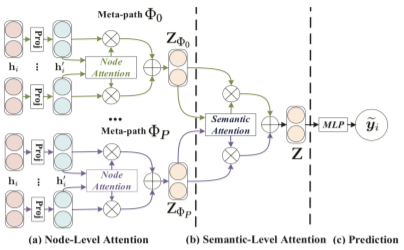
GAT模型的总体架构
【NIPS 2019】Graph Transformer Networks
作者:Seongjun Yun, Minbyul Jeong, Raehyun Kim, Jaewoo Kang, Hyunwoo J. Kim
论文地址:https://arxiv.org/pdf/1911.06455.pdf
导读:论文在GNN网络上使用meta-path做节点分类与聚类,主要解决两个问题:(1)传统的 node representation 只利用了图的结构,不能针对特定任务优化;(2)基于 meta-path 的方法大部分基于人工定义的 meta-path,并且没有考虑每种 meta-path 的重要性。该方法在 Graph Transformer 层基于不同的关系邻接矩阵自动学习 C 种不同的 meta-path;然后将多条 meta-path 的矩阵用于 GCN 层上来学习节点表达。模型三个数据集上的表现,到达到了 SOTA 效果,超越了之前的 SOTA 模型 HAN。
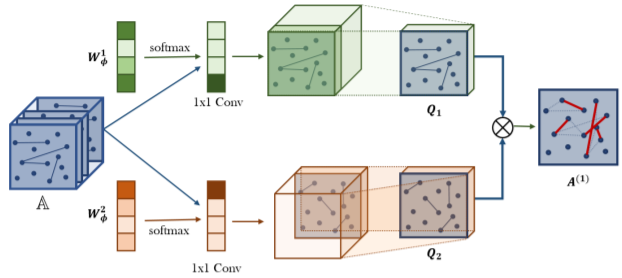
Graph Transformer Layer
本期内容:盛泳潘 黄豪
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢