标题:特伦托大学、哥本哈根大学|Vision-and-Language or Vision-for-Language? On Cross-Modal Influence in Multimodal Transformers(视觉与语言还是视觉语言? 多模态变换器中的跨模态影响分析)
https://arxiv.org/pdf/2109.04448v1.pdf
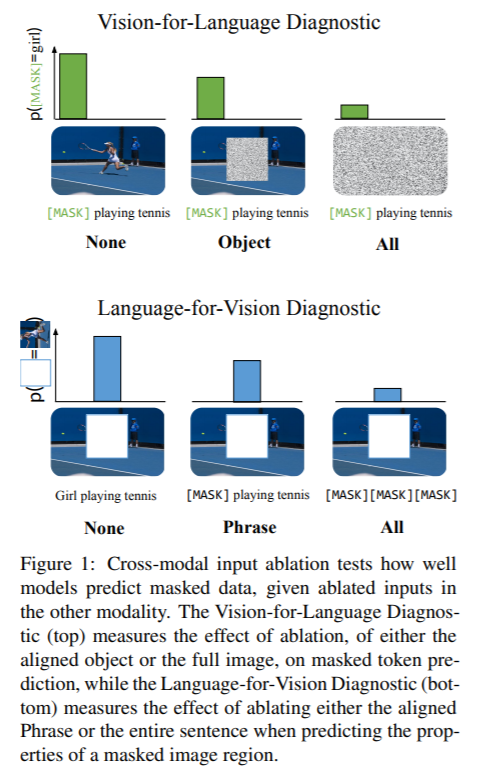
内容中包含的图片若涉及版权问题,请及时与我们联系删除

https://arxiv.org/pdf/2109.04448v1.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除
沙发等你来抢

评论
沙发等你来抢