
【论文标题】Using BERT to identify drug-target interactions from whole PubMed
【作者团队】, , ,
【发表时间】2021/09/11
【机 构】赫尔辛基大学
【论文链接】https://doi.org/10.1101/2021.09.06.459087
【结果链接】https://dataset.drugtargetcommons.org/
药物-靶点相互作用(DTIs)对于药物再利用和药物机制的阐明至关重要,它们被收集在大型数据库中,如ChEMBL、BindingDB、DrugBank和DrugTargetCommons。然而,提供这种数据的研究数量(约10万)可能只占PubMed上所有包含实验性DTI数据的研究的一小部分,找到这些研究并提取实验信息是一项具有挑战性的任务,因此迫切需要通过机器学习来提取和整理DTIs。为此,本文开发了基于BERT算法的文本挖掘文档分类器。由于DTI数据密切依赖于用于生成它的检测方法 ,本文还旨在纳入预测检测方法的功能。结果本文的新方法识别并提取了210万份研究报告中的DTIs,这些研究报告以前没有被纳入公共DTI数据库。本文获得了约99%的准确率来识别含有药物-目标对的研究,预测检测格式的准确率为~90%,这为今后的研究留下了改进的空间。本研究中的BERT模型是鲁棒的,所提出的工作流可以用来识别新的和以前被忽视的含有DTI的研究,并自动提取DTI数据点。总的来说,本文的方法在机器辅助DTI提取和整理方面取得了重大进展。本文希望它能成为药物机制发现和再利用的有益补充。
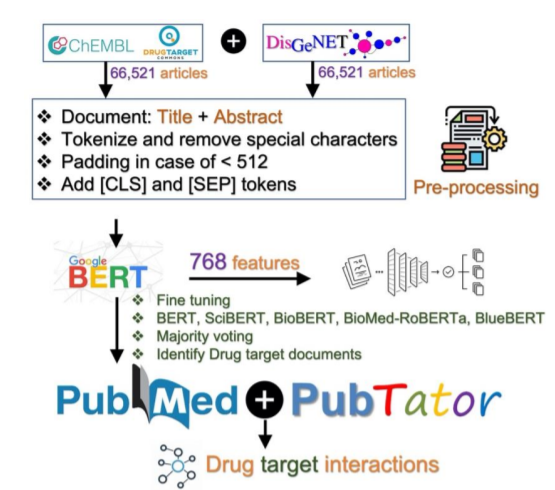
识别含有药物-目标生物活性数据的新研究的工作流程。研究的药物和蛋白质实体从PubTator数据集中整合出来。最终的输出包含对可能有DTIs的约1850万项研究的预测。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢