
1. 【CIKM2021】 Single Node Injection Attack against Graph Neural Networks
地址:https://arxiv.org/abs/2108.13049
代码地址:https://github.com/TaoShuchang/G-NIA
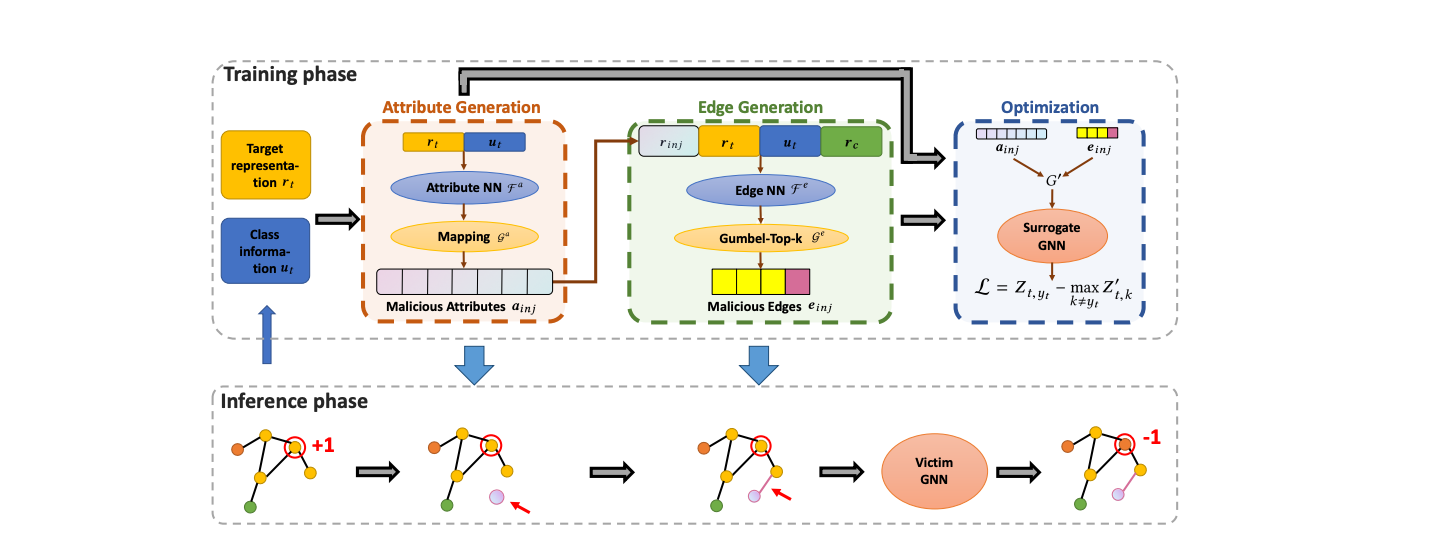
导读:图神经网络(GNN)节点注入攻击是一种新兴且实用的攻击场景,攻击者通过注入恶意节点而不是修改原始节点或边来影响GNN的性能。文章着力于单节点注入,即在测试阶段只允许攻击者注入一个节点来损害 GNN的性能。文章提出提出了一种基于优化的方法来探索单节点注入规避攻击的性能上限。实验结果表明,三个公共数据集上的100%、98.60%和94.98%的节点即使只注入一个边缘的节点也能成功攻击,证实了单节点注入规避攻击的可行性。进一步,为了解决优化的计算复杂性这一困境,提出了一种可推广的节点注入攻击模型,即G-NIA,以在保证攻击性能的同时提高攻击效率。实验是在三个著名的 GNN 上进行的。我们提出的 G-NIA 显着优于最先进的基线,并且在推理时比基于优化的方法快500倍。
2. 【arXiv2021】Jointly Attacking Graph Neural Network and its Explanations
地址: https://arxiv.org/abs/2108.03388
代码地址: https://github.com/DSE-MSU/DeepRobust/tree/master/deeprobust/graph
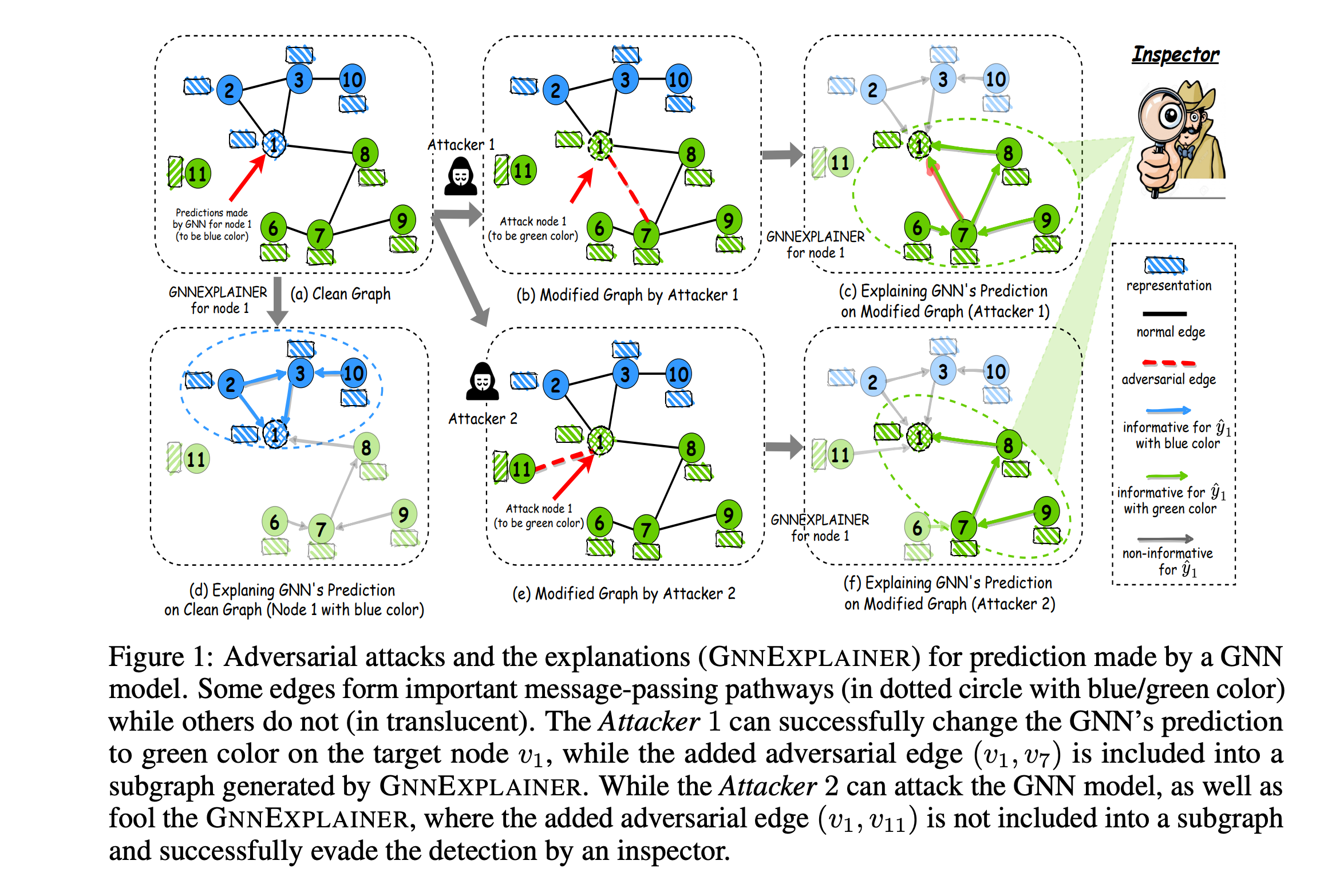
导读: 过去几年,图神经网络 (GNN) 取得了巨大成功,但最近的研究表明,GNN 非常容易受到对抗性攻击,攻击者可以通过修改图来误导 GNN 的预测。另一方面,GNN 的解释 (GNNExplainer) 通过生成对其预测最有影响的小子图和特征,可以更好地理解经过训练的 GNN 模型。在本文中,文章进行实证研究以验证 GNNExplainer 可以作为检查工具并有可能检测图的对抗性扰动。进一步文章调查了一个有趣的问题:
图神经网络的解释性是否可以用来攻击图神经网络?
该问题颇有”以子之矛,攻子之盾”的感觉。文章通过提出一种新颖的攻击框架 (GEAttack) 对这个问题给出了肯定的答案,该框架可以通过同时利用 GNN 模型及其解释的漏洞来攻击它们。在各种真实世界数据集下对两个解释器(GNNExplainer 和 PGExplainer)的大量实验证明了所提出方法的有效性。
3. 【CCS2021】A Hard Label Black-box Adversarial Attack Against Graph Neural Networks
地址:https://arxiv.org/abs/2108.09513
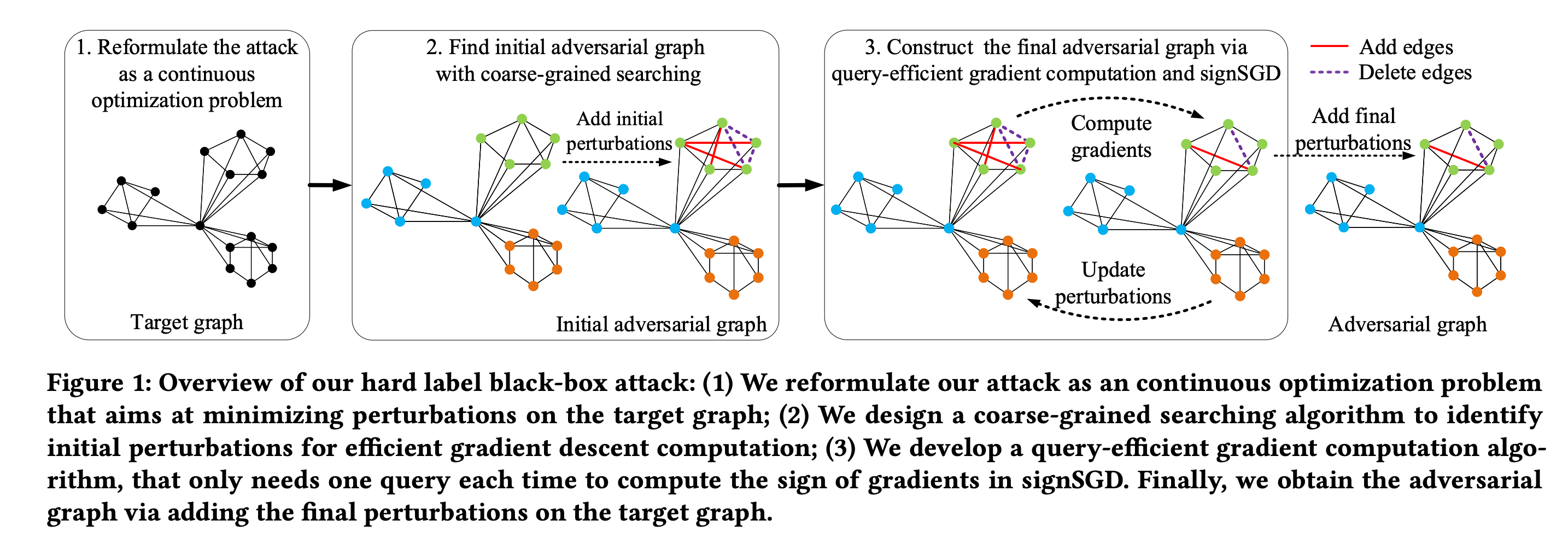
导读:文章也关注到图神经网络的易被攻击的特点,通过扰乱图结构对针对 GNN 进行图分类的对抗性攻击进行了系统的研究。
文章专注于“硬标签黑盒攻击”,其中攻击者对目标 GNN 模型一无所知,只能通过查询目标来获得预测标签来实现这一目标,文章设定攻击是一个优化问题,其目标是在保持高攻击成功率的同时,最小化图中要扰动的边数。原优化问题求解是困难的,进一步把优化问题放宽为一个容易解决的问题,在理论收敛的保证下可解。
文章在三个真实世界数据集上的实验结果表明,可以有效地攻击具有代表性的 GNN,用于图分类的查询和扰动更少。
进一步,还在两种防御模型下评估了攻击的有效性:一种是精心设计的对抗图检测器,另一种是目标 GNN 模型本身配备了防御以防止对抗图生成。实验结果表明,这样的防御不够有效,这凸显了更高级的防御。
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢