
【论文标题】Transformers in Vision: A Survey
【作者团队】Salman Khan, Muzammal Naseer, Munawar Hayat, Syed Waqas Zamir, Fahad Shahbaz Khan, and Mubarak Shah
【发表时间】2021/09/08
【机 构】MZB 人工智能大学,起源人工智能研究院,莫奈什大学等
【论文链接】https://arxiv.org/abs/2101.01169v3
Transformer模型在自然语言任务上取得的惊人结果,吸引了视觉界研究它们在计算机视觉问题上的应用。在其突出的优点中,Transformer能够对输入序列元素之间的长期依赖关系进行建模,并且与如LSTM的递归网络相比,支持序列的并行处理。此外,Transformer的直接设计允许使用类似的处理块来处理如图像、视频、文本和语音的多种模式,并展示了对大容量网络和巨大数据集的出色可扩展性。这些优势导致了使用Transformer网络的一些视觉任务取得了令人振奋的进展。本综述旨在提供计算机视觉学科中Transformer模型的全面概述。本文首先介绍了Transformer成功背后的基本概念,即自注意力、大规模预训练和双向编码。然后,本文介绍了Transformer在视觉中的广泛应用,包括流行的识别任务(如图像分类、物体检测、动作识别和分割)、生成模型、多模态任务(如视觉问题回答、视觉推理和视觉定位)、视频处理(如活动识别、视频预测)、低层次视觉(如图像超分辨率、图像增强和着色)和3D分析(如点云分类和分割)。本文比较了流行技术在架构设计和实验价值方面各自的优势和局限。最后,本文对开放的研究方向和未来可能的工作进行了分析。
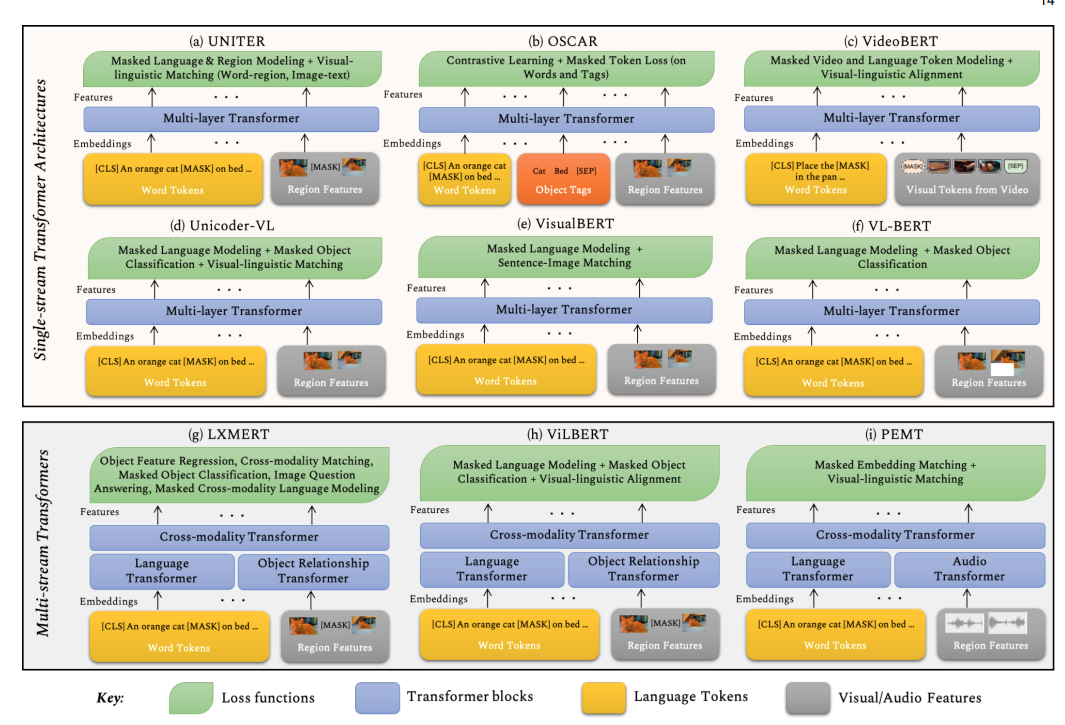
用于计算机视觉中多模态任务的Transformer模型的概述。这一类的变换器设计可以分为单流(UNITER, OSCAR, VideoBERT, Unicoder-VL, VisualBERT 和 VL-BERT)和双流结构(LXMERT , ViLBERT 和 PEMT)。模型之间的一个关键区别是损失函数的选择。虽然大多数的多模式方法都集中在作为视觉数据的图像上,但VideoBERT和PEMT被设计为在视频流上工作,并利用独特的模式,例如视频中的音频信号。
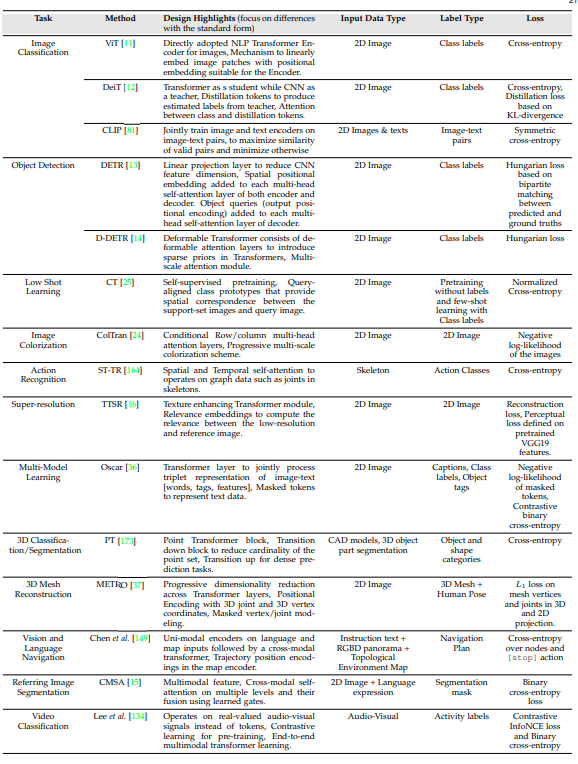
上图展示了有代表性的计算机视觉应用,对不同变体的Transformer所采用的关键设计选择进行了总结。主要的变化涉及到具体的损失函数选择、架构修改、不同的位置嵌入和输入数据模式的变化。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢