
论文题目:An Empirical Study of GPT-3 for Few-Shot Knowledge-Based VQA
作者:Zhengyuan Yang、Lijuan Wang
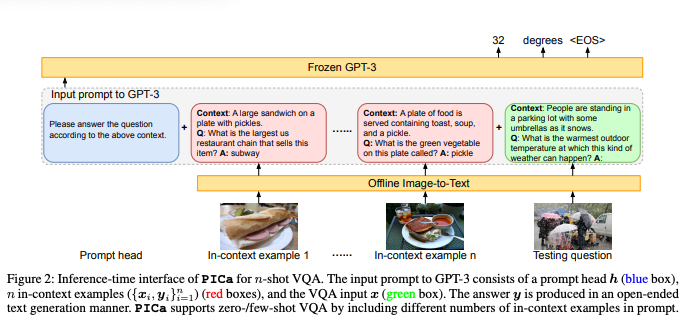
简介:本文探讨了大模型在VQA中的应用。基于知识的视觉问答涉及不出现在图像中外部知识。现有方法首先从外部资源中检索知识,然后对选定的信息进行推理知识、输入图像和答案预测问题。然而,这种两步法可能会导致不匹配,从而可能限制VQA的性能。例如,检索到的知识可能是嘈杂的和不相关的,在推理过程中重新嵌入的知识特征可能会偏离其原始含义知识库 (KB)。为了应对这一挑战,作者提出了 PICa,这是一种简单而有效的方法,它通过使用图像标题提示GPT3,用于基于知识的VQA。受GPT-3在知识检索和问答方面的强大启发,而不是像以前那样使用结构化的知识库工作,我们将GPT-3视为隐式和非结构化的知识库可以共同获取和处理相关知识。具体来说,作者首先将图像转换为GPT-3可以理解的标题(或标签),然后适配GPT-3解决VQA只需提供一些上下文,即可完成任务VQA示例。作者通过谨慎进一步提高性能调查:(i)哪种文本格式最能描述图像内容,以及 (ii) 如何更好地选择和使用上下文中的样本。 PICa首次将GPT-3用于多模态任务。仅使用16个样本,在OK-VQA数据集,PICa就以绝对+8.6分的最先进技术水平超过了竞争对手。我们还在 VQAv2 上对PICa进行了基准测试,PICa也表现出不错的少样本性能。
论文下载:https://arxiv.org/pdf/2109.05014v1.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢