简介
前段时间FlagAI支持了ViT模型,并且可以一键切换不同的运行环境(GPU、DDP、deepspeed)进行加速,还没有了解过的小伙伴可以移步 想要一键加速ViT模型?试试这个开源工具!一探究竟!
最近,FlagAI的模型库又有两位成员加入,分别为SwinTransformerV1、和SwinTransformerV2,我们分别来介绍一下。
FlagAI目前陆续支持不同的视觉模型,可以方便的支持模型下载,参数加载,训练,推理,无缝切换多GPU训练,deepspeed显存优化,训练加速等全流程操作。尤其针对于加速,显存优化,可以方便的通过设置不同的运行参数即可轻松实现!

Swin Transformer
Swin Transformer这篇文章在发出时便引起了很大的反响,各大微信公众号都在推送,站上了各种计算机视觉领域的比赛排行榜的榜首,颇有当年Bert模型刚发布的气势,后面由于其实力强劲,获得了ICCV2021最佳论文(马尔奖),在计算机视觉领域引起了非常强烈的反响!本文会稍微介绍一下相关知识,想要仔细学习还是推荐阅读论文或更详细的讲解文章。附论文地址:https://arxiv.org/abs/2103.14030
引言
Transformer最开始流行于NLP领域,后面逐渐向CV领域扩张,ViT模型便是其中的开山之作,利用较大的卷积核不重叠的进行卷积操作,于是将一整张图像编码成一个一个的特征token,如图:
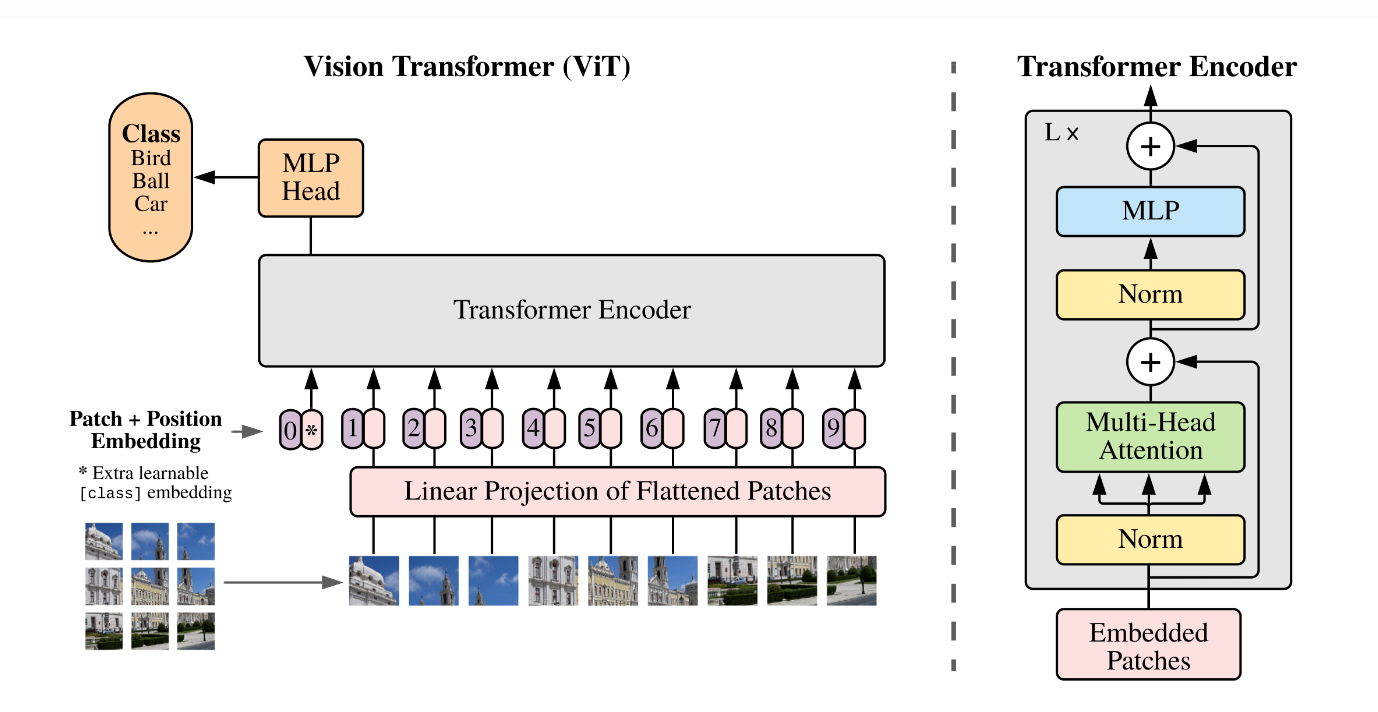
于是Transformer结构便可以利用Self-attention机制计算不同图像特征token之间的影响,加权融合,传入下一层。
但是,ViT结构直接将图像进行降采样到原来是1/16或1/32,不像传统CV中会逐步降采样提取多尺度特征,并且Self-attention机制计算全局注意力导致计算量与显存占用较大,那么有没有一种好的办法解决目前的困境呢?Swin Transformer就来了!
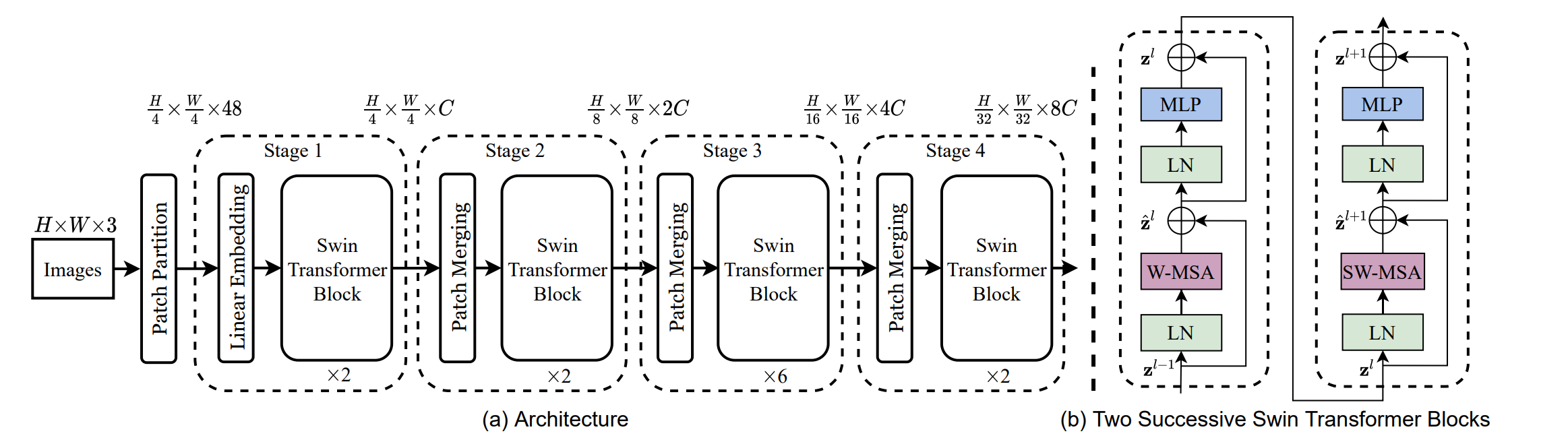
Shifted windows attention 与多尺度特征提取
Swin Transformer提出了一个基于滑动窗口的局部注意力操作,引入了类似CNN的局部性,同时也将全局的注意力转变为局部,大大提高了计算效率,那么还一个问题,因为窗口之间是无重叠的,导致窗口之间没有信息交互。于是Swin Transformer对窗口划分进行移动,使得连续两层的窗口划分不同,相邻的组即可进行高效的信息交互。另外,Swin Transformer在计算局部注意力时,还使用了相对位置编码。
由于提升了计算效率,Swin Transformer也支持提取多尺度特征了,可以更好的应用在分割、检测等下游任务中。
实验结果表明,Swin Transformer在多个任务中均大幅超越了ViT结构,尤其在检测,分割等任务上表现优异,感兴趣的同学可以翻看论文最后的实验部分。
Swin Transformer V2
随着V1的成功,团队最近又研究出了一个新版本,也就是Swin Transformer V2,这个版本对一些细节问题进行了优化,可以适配不同的图像分辨率,并且可以让模型构建的更大,发表在了CVPR2022上,也是一篇不错的工作。论文链接:https://arxiv.org/abs/2111.09883
让模型变得更大
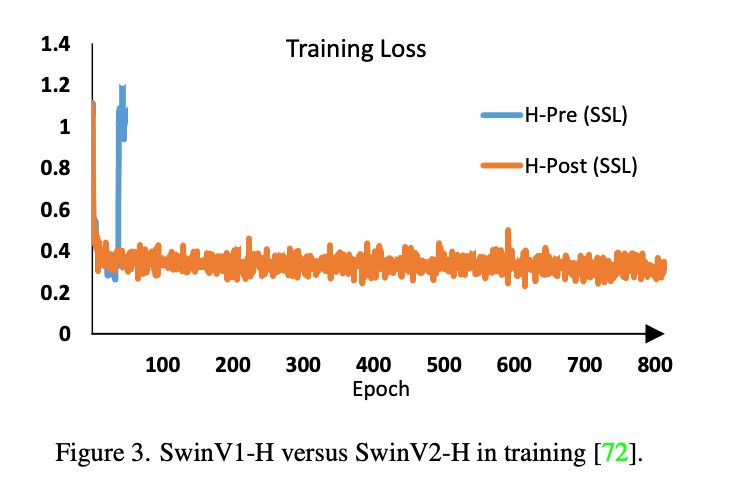
首先,通过加深层数让模型变得更大,参数量更多,但是会发现随着模型增大,训练也容易出现不稳定,因此提出了1. Post-norm 2. Cosine similarity based self-attention 用来稳定每层的输出。其中post-norm就是将每层计算完才进行标准化,而不是计算之前;同时将Q.dot(K)变为cosine similarity,也可以使得计算结果稳定在某个范围内。
适配不同分辨率输入
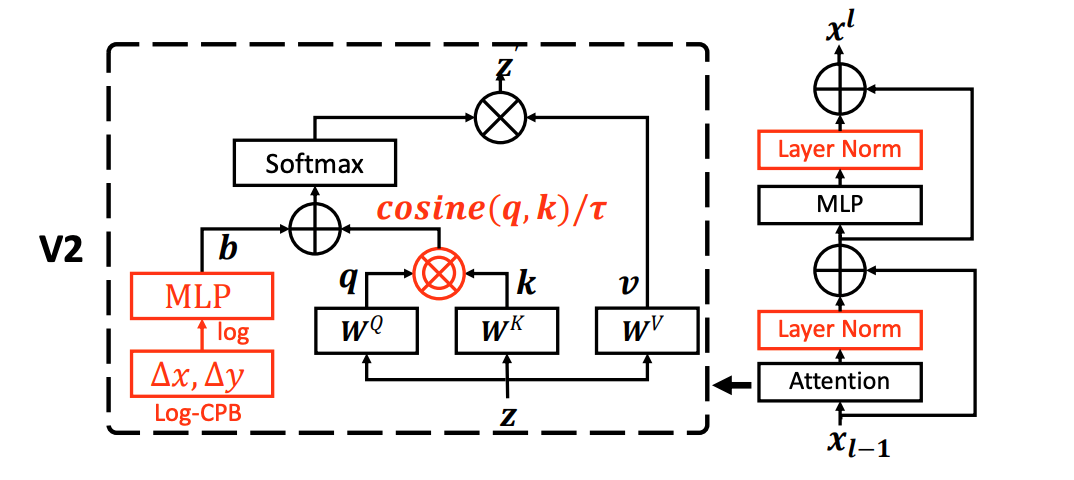
当预训练过程中的输入分辨率与下游任务的输入分辨率不匹配时,导致相对位置编码的偏移,于是Swin Transformer V2提出了Continuous relative position bias 和 Log-spaced coordinates,其中Continuous relative position bias直接通过神经网络自适应的生成相对位置编码;Log-spaced coordinates 利用坐标变换将位置编码的外推率降低,更好的适配不同分辨率的情况。详细可以查阅官方论文。
FlagAI一键调用、加速
代码位置
FlagAI目前已经支持Swin Transformer V1 与 Swin Transformer V2,样例数据为Imagenet,数据与代码位于FlagAI官方仓库中的examples目录下:https://github.com/FlagAI-Open/FlagAI/tree/master/examples
-examples
-swinv1
-imagenet2012
-training_swinv1.py
-inference_swinv1.py
-swinv2
-imagenet2012
-training_swinv2.py
-inference_swinv2.py
其中image2012为样例数据集,可以直接运行训练与推理代码,如果想在imagenet数据集上进行完整的实验,自行加载imagenet数据集即可。
模型支持
目前FlagAI支持
Swin Transformer V1 :
- swinv1-base-patch4-window7-224
Swin Transformer V2中:
- swinv2-base-patch4-window16-256
- swinv2-small-patch4-window16-256
- swinv2-base-patch4-window8-256
训练代码
以下代码为使用pytorchDDP模式进行训练,使用4GPUs,如果切换deepspeed模式加速,修改env_type="deepspeed"即可。
|
import os
import torch
import torchvision.transforms as transforms
import torchvision.datasets as datasets
from flagai.trainer import Trainer
from flagai.auto_model import AutoLoader
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
data_path = "./imagenet2012/"
# use DDP for training by 4 gpus.
trainer = Trainer(env_type="pytorchDDP",
epochs=10,
experiment_name="swinv2_imagenet_ddp",
batch_size=32,
weight_decay=1e-3,
warm_up=0.1,
lr=5e-5,
save_interval=100,
eval_interval=100,
log_interval=10,
num_gpus=4,
hostfile="./hostfile",
training_script="training_swinv2.py"
)
# swinv2 model_name support:
# 1. swinv2-base-patch4-window16-256,
# 2. swinv2-small-patch4-window16-256,
# 3. swinv2-base-patch4-window8-256
loader = AutoLoader(task_name="classification",
model_name="swinv2-base-patch4-window8-256",
num_classes=1000)
model = loader.get_model()
# build imagenet dataset
def build_dataset(root):
traindir = os.path.join(root, 'train')
valdir = os.path.join(root, 'val')
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
train_dataset = datasets.ImageFolder(
traindir,
transforms.Compose([
transforms.RandomResizedCrop(256),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize
])
)
val_dataset = datasets.ImageFolder(
valdir,
transforms.Compose([
transforms.Resize((256, 256)),
transforms.ToTensor(),
normalize
])
)
return train_dataset, val_dataset
def collate_fn(batch):
images = torch.stack([b[0] for b in batch])
if trainer.fp16:
images = images.half()
labels = [b[1] for b in batch]
labels = torch.tensor(labels).long()
return {"images": images, "labels": labels}
def top1_acc(pred, labels, **kwargs):
pred = pred.argmax(dim=1)
top1_acc = pred.eq(labels).sum().item() / len(pred)
return top1_acc
if __name__ == '__main__':
print("building imagenet dataset......")
train_dataset, val_dataset = build_dataset(root=data_path)
print("training......")
optimizer = torch.optim.Adam(model.parameters(), lr=5e-5)
trainer.train(model,
train_dataset=train_dataset,
valid_dataset=val_dataset,
collate_fn=collate_fn,
optimizer=optimizer,
metric_methods=[["top1_acc", top1_acc]],
find_unused_parameters=False)
|
推理代码
以下代码为使用预训练好的模型直接在imagenet数据集上进行推理,能够复现官方准确率。
|
import torch
import os
from torchvision import transforms
from torch.utils.data import Dataset, DataLoader
import torchvision.datasets as datasets
from tqdm import tqdm
from flagai.auto_model.auto_loader import AutoLoader
data_path = "./imagenet2012/"
# swinv2 model_name support:
# 1. swinv2-base-patch4-window16-256,
# 2. swinv2-small-patch4-window16-256,
# 3. swinv2-base-patch4-window8-256
loader = AutoLoader(task_name="classification",
model_name="swinv2-small-patch4-window16-256")
model = loader.get_model()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.eval()
model.to(device)
# imagenet loader
def data_loader(root, batch_size=256, workers=1):
valdir = os.path.join(root, 'val')
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
val_dataset = datasets.ImageFolder(
valdir,
transforms.Compose([
transforms.Resize((256, 256)),
transforms.ToTensor(),
normalize
])
)
val_loader = DataLoader(val_dataset,
batch_size=batch_size,
shuffle=False,
num_workers=workers
)
return val_loader
@torch.no_grad()
def test(model,data_loader):
model.eval()
top1_acc = 0.0
top5_acc = 0.0
for step, (inputs, labels) in tqdm(enumerate(data_loader), total=len(data_loader)):
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)["logits"]
_, top1_preds = outputs.max(1)
top1_acc += top1_preds.eq(labels).sum().item()
top5_pred = outputs.topk(5, 1, True)[1]
top5_acc += top5_pred.eq(labels.view(-1, 1).expand_as(top5_pred).to(device)).sum().item()
print(
"test_top1_acc [{top1_acc}], test_top5_acc [{top5_acc}] \n".format(
top1_acc=top1_acc/len(data_loader.dataset),
top5_acc=top5_acc/len(data_loader.dataset),
)
)
if __name__ == '__main__':
val_loader = data_loader(data_path, batch_size=8, workers=8)
test(model, val_loader)
|
小结
不难发现,使用FlagAI框架,可以非常轻松的构建好并下载对应模型,切换不同的训练模式进行多GPU训练,加速,并且开始训练。如果想切换为自己的数据集,只需要修改dataset即可。
此外,通过这次的例子,还可以看出FlagAI可以非常方便的定义自己的评价指标,通过定义评价函数,传入trainer,便可以很方便的实现多个评价指标的计算。
FlagAI特点
FlagAI飞智是一个快速、易于使用和可扩展的AI基础模型工具包。 支持一键调用多种主流基础模型,同时适配了中英文多种下游任务。
- FlagAI支持最高百亿参数的悟道GLM(详见GLM介绍),同时也支持BERT、RoBERTa、GPT2、T5 模型、Meta OPT模型、ViT系列模型和 Huggingface Transformers 的模型。
- FlagAI提供 API 以快速下载并在给定(中/英文)文本上使用这些预训练模型,你可以在自己的数据集上对其进行微调(fine-tuning)或者应用提示学习(prompt-tuning)。
- FlagAI提供丰富的基础模型下游任务支持,例如文本分类、信息提取、问答、摘要、文本生成、图文匹配、图像分类等,对中英文都有很好的支持。
- FlagAI由三个最流行的数据/模型并行库(PyTorch/Deepspeed/Megatron-LM)提供支持,它们之间实现了无缝集成。 在FlagAI上,你可以用不到十行代码来并行你的训练、测试过程,也可以方便的使用各种模型提速技巧。
开源项目地址:https://github.com/BAAI-Open/FlagAI

内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢