
来自今天的爱可可AI前沿推介
[CV] Co-training 2^L Submodels for Visual Recognition
H Touvron, M Cord, M Oquab, P Bojanowski, J Verbeek, H Jégou
[Meta AI & Sorbonne University]
面向视觉识别的2^L子模型协同训练
要点:
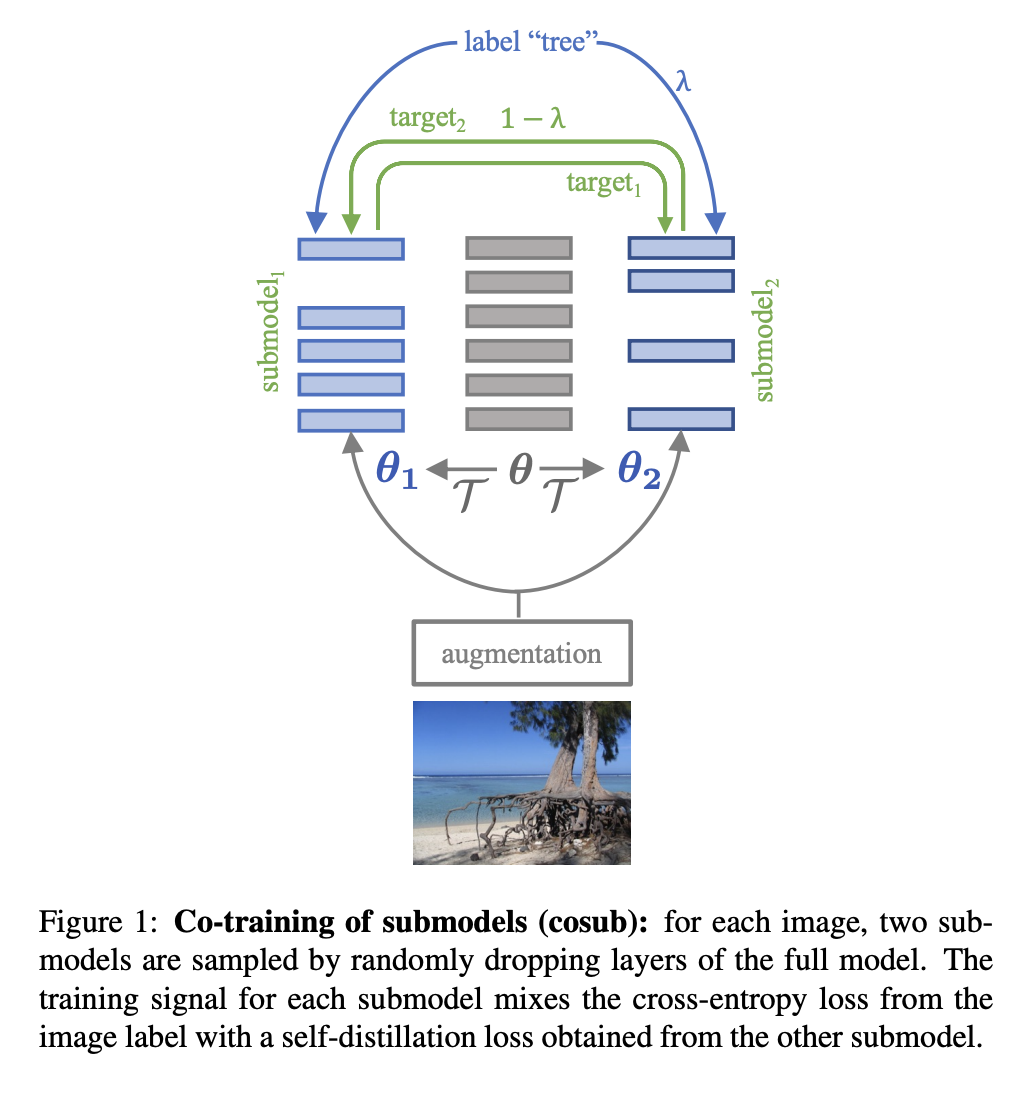
1. 提出CoSub,一种正则化方法,用一组权重来协同训练子模型,不涉及预训练的外部模型或时间平均;
2. 在用于图像分类和语义分割的多种架构(例如 ViT、ResNet、RegNet、PiT、XCiT、Swin、ConvNext)上验证了该方法,显著改善了大多数模型的训练;
3. 提供了一个有效的实现来动态子采样模型,并表明子模型本身就是有效的模型,即使有显著的修剪。
摘要:
本文提出子模型协同训练,一种与协同训练、自蒸馏和随机深度相关的正则化方法。给定一个要训练的神经网络,对于每个样本,隐式地实例化两个变化的网络,即“子模型”,具有随机深度:只对层的一个子集进行激活。每个网络都充当另一个网络的软教师,通过提供损失来补充 one-hot 标签提供的常规损失。该方法称为 cosub,使用一组权重,不涉及预训练的外部模型或时间平均。实验表明,子模型协同训练可有效训练骨干以完成图像分类和语义分割等识别任务。所提出方法与多种架构兼容,包括 RegNet、ViT、PiT、XCiT、Swin 和 ConvNext。所提出的训练策略在可比较的环境中改善了其结果。
We introduce submodel co-training, a regularization method related to co-training, self-distillation and stochastic depth. Given a neural network to be trained, for each sample we implicitly instantiate two altered networks, "submodels'', with stochastic depth: we activate only a subset of the layers. Each network serves as a soft teacher to the other, by providing a loss that complements the regular loss provided by the one-hot label. Our approach, dubbed cosub, uses a single set of weights, and does not involve a pre-trained external model or temporal averaging.Experimentally, we show that submodel co-training is effective to train backbones for recognition tasks such as image classification and semantic segmentation. Our approach is compatible with multiple architectures, including RegNet, ViT, PiT, XCiT, Swin and ConvNext. Our training strategy improves their results in comparable settings. For instance, a ViT-B pretrained with cosub on ImageNet-21k obtains 87.4% top-1 acc. @448 on ImageNet-val.
论文链接:https://arxiv.org/abs/2212.04884



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢