
POINT-E里的“POINT”显然对应点云,“E”是“efficiency”,生成的样本质量还不如业界最好的(比如Google的DreamFusion),但生成速度比较快。也许这是OpenAI第一时间就开源的原因?之前其他好东西都只开放API,留着收费了。:)

论文: https://arxiv.org/abs/2212.08751
作者:Alex Nichol, Heewoo Jun, Prafulla Dhariwal, Pamela Mishkin, Mark Chen(前两人是主要作者)
Alex Nichol从LinkedIn来看之前是自由程序员长达十年,也没发表过什么论文,2017年加入OpenAI后成为骨干(DBLP),是GLIDE的一作,DALL-E 2的主要作者之一。
Heewoo Jun(DBLP) 2017-2018年曾在百度硅谷研究院工作。他是Jukebox的主要作者之一。
Prafulla Dhariwal(LinkedIn)2017年毕业于MIT本科计算机与数学专业,2016年进入OpenAI实习,现在是研究科学家。他是GLIDE、DALL-E 2、Jukebox的主要作者之一。也参与了GPT-3的工作,排名在四位共同一作之后。
Pamela Mishkin(LinkedIn)Williams College本科,2017-2018年在剑桥大学读科技政策硕士。然后做过产品经理、分析师、程序员。2020年通过Scholars项目加入OpenAI。她应该是偏安全伦理背景。
Mark Chen(LinkedIn)2012年本科毕业于MIT,从事量化交易几年。2018年加入OpenAI。
摘要
While recent work on text-conditional 3D object generation has shown promising results, the state-of-the-art methods typically require multiple GPU-hours to produce a single sample. This is in stark contrast to state-of-the-art generative image models, which produce samples in a number of seconds or minutes. In this paper, we explore an alternative method for 3D object generation which produces 3D models in only 1-2 minutes on a single GPU. Our method first generates a single synthetic view using a text-to-image diffusion model, and then produces a 3D point cloud using a second diffusion model which conditions on the generated image. While our method still falls short of the state-of-the-art in terms of sample quality, it is one to two orders of magnitude faster to sample from, offering a practical trade-off for some use cases. We release our pre-trained point cloud diffusion models, as well as evaluation code and models, at this https URL.
虽然最近关于文本条件 3D 对象生成的工作已经显示出很有前景的结果,但最先进的方法通常需要多个 GPU 小时来生成单个样本。 这与最先进的生成图像模型可以在几秒或几分钟内生成样本形成鲜明对比。 在本文中,我们探索了一种用于生成 3D 对象的新方法,仅需 1-2 分钟即可在单个 GPU 上生成 3D 模型。 我们的方法首先使用文本到图像的扩散模型生成单个合成视图,然后以生成的图像为条件,使用第二个扩散模型生成 3D 点云。 虽然我们的方法在样本质量方面仍未达到最先进的水平,但它的采样速度要快一到两个数量级,为某些用例提供了实际的权衡方案。 预训练的点云扩散模型以及评估代码和模型已发布在GitHub。
GitHub地址: https://github.com/openai/point-e
论文里的原理图:
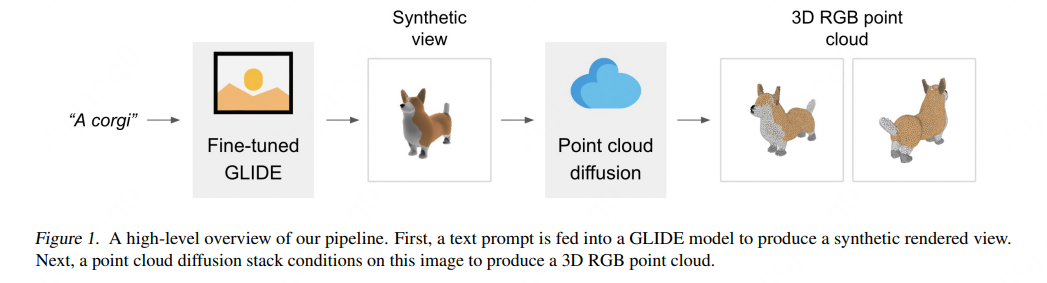
两步:先用了一个30亿参数的GLIDE模型,从文到合成视图,然后再用一个点云扩散模型生成点云;这一步又分为两个小步骤:先基于合成视图生成一个粗略点云(1,024 个点),然后以低分辨率点云和合成视图为条件生成一个精细点云(4,096 个点)。
模型可以直接在HuggingFace里试用 https://huggingface.co/spaces/openai/point-e 。
媒体报道
TechCrunch https://techcrunch.com/2022/12/20/openai-releases-point-e-an-ai-that-generates-3d-models/
SiliconANGLE https://siliconangle.com/2022/12/20/openai-develops-ai-system-capable-generating-3d-models/
讨论
https://news.ycombinator.com/item?id=34064345
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢