
微软推出语音模型VALL-E,该模型通过三秒钟音频样本就可模拟一个人的声音,同时可以保持说话人的情感语气。VALL-E除了可进行语音生成和编辑,还能够模仿语音环境,目标是尽量是学会一个人的声音特征。

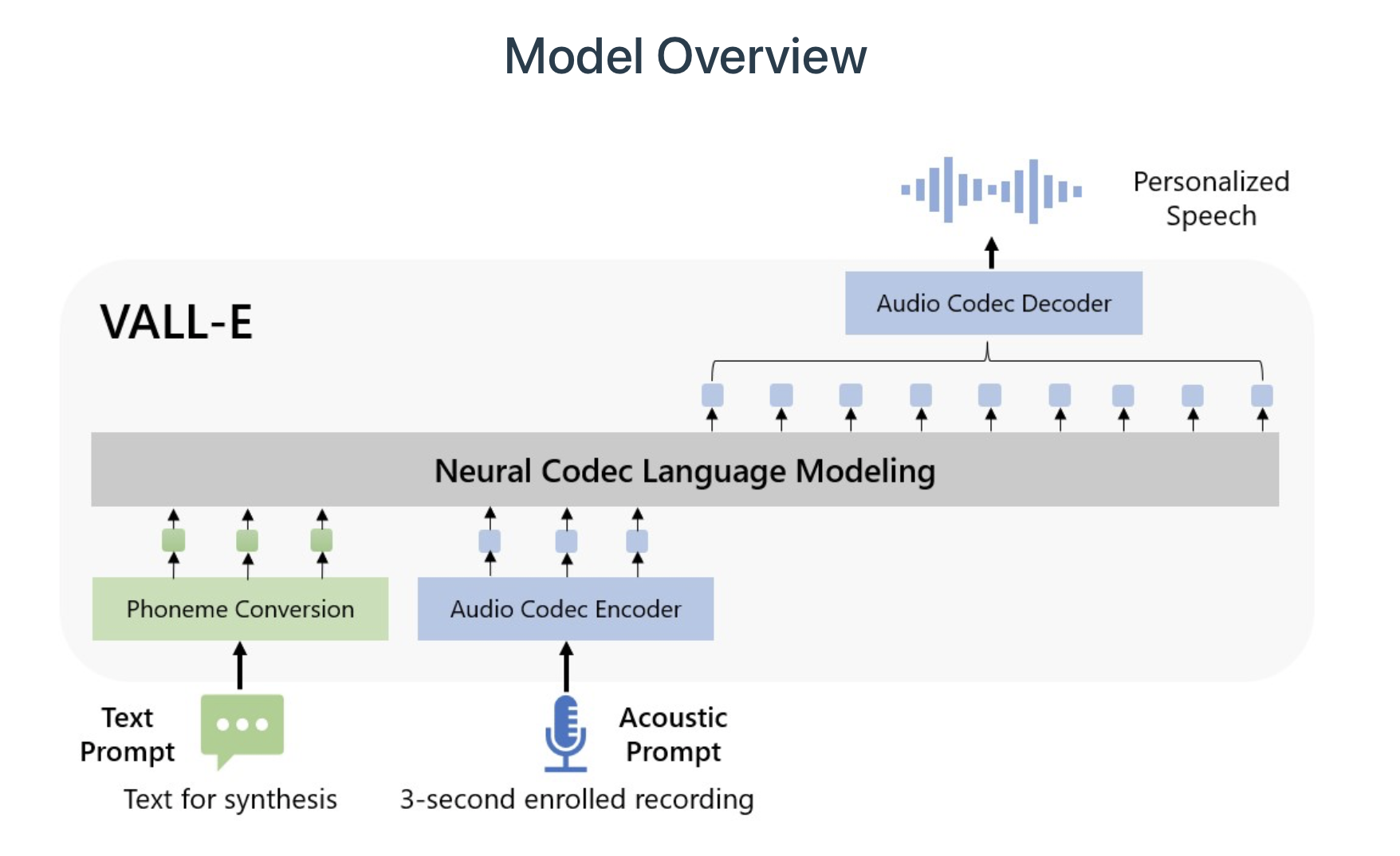
目前,微软在Meta的LibriLight的音频库加入了VALL-E的语音合成功能。音频库包括60,000小时英语演讲内容,均为LibriVox公共领域有声读物。
VALL-E提供了数十个人工智能模型的音频示例,研究人员只将三秒钟的“扬声器提示”样本和文本字符串(他们希望语音说的话)输入VALL-E即可生成。

除了保留声色和情感音调外,VALL-E还可以模仿样本音频的“声学环境”。例如,如果样本来自电话,音频输出将模拟电话的合成输出中的声学和频率特性,让它听起来也像一个电话。
目前研究员意识到VALL-E可能会“骗人”,因此微软VALL-E代码尚未开源,他们表示:由于VALL-E的合成语音功能。也许会带来潜在风险,比如欺骗语音识别或冒充特定的声音,需要规避这个风险,可以再建立一个检测模型来区分音频剪辑是否由VALL-E合成。
相关信息
https://arstechnica.com/information
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢