
书接前回,我们在这里《FlagPerf,开箱即用的AI芯片Benchmark平台》介绍了FlagPerf是什么和怎么用。这次呢,我们给各位喜欢自己动手的小伙伴们准备了开发教程。欢迎大家一起给FlagPerf添砖加瓦。
1.FlagPerf架构和代码结构简介
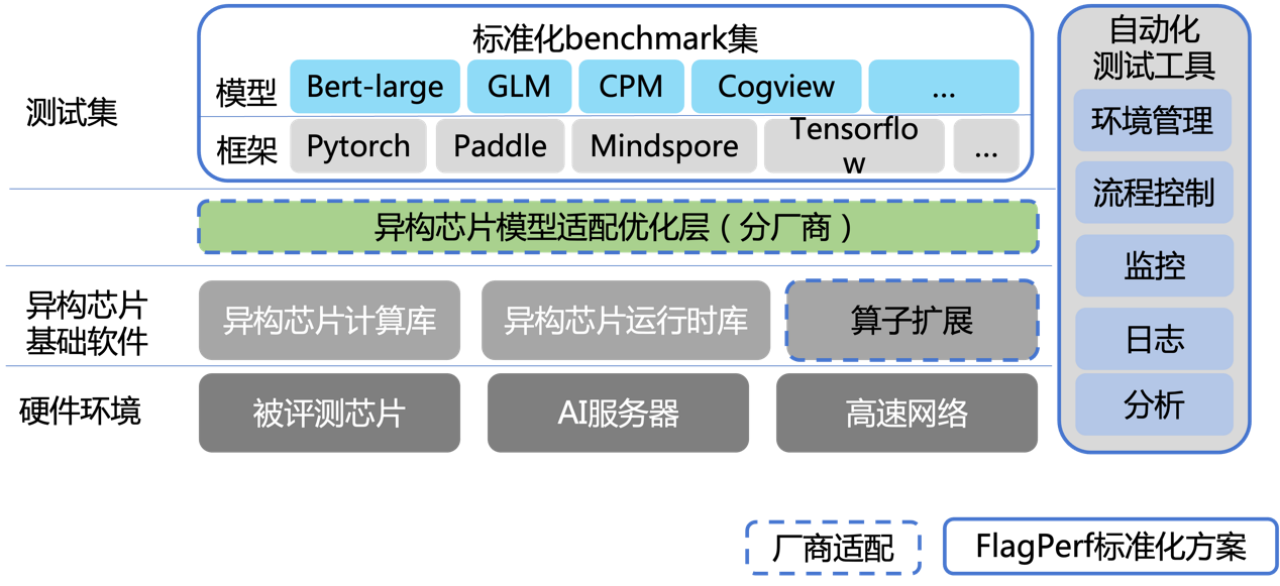
在动手之前,咱们先一起看看FlagPerf的整体架构,以便了解工作内容。FlagPerf目前是这样子的:
最右侧是自动化测试工具,包括了整个benchmark任务生命周期管理 ,包括每个测试任务的容器环境准备、任务启动、任务运行过程中系统信息的收集、等待任务结束后的日志收集等等。
咱们添加一款新框架时,在这部分主要解决容器环境的准备、容器内测试任务的启动即可,其余部分皆有通用的模块支持实现。
左侧上面的蓝色框内是标准化的benchmark测试集。包括标准化的模型训练benchmark case实现,和多个框架的支持。这里也涉及到AI框架的添加,主要在通用的benchmark driver中实现AI框架的driver支持。同样的,训练中打印日志、注册和处理Event等已有通用的模块处理。完全不需要你来操心。如果你觉得哪里能做得更完善,也可以一并修改了提PR哦。
左侧绿色的“异构芯片模型适配优化层”是异构芯片厂商需要适配的啦,咱们这里可以不考虑。
那么,咱们要添加一个框架支持,具体要做什么呢?
咱们先看这张地图,FlagPerf目录结构,下载代码后,执行tree -L 3命令就可以看到(这里只列出咱们关心的哈):
└── training
l── benchmarks #标准化benchmark case实现,每个case一个独立的目录,为/。
l── # 放厂商的扩展,比如nvidia,这个部分包括benchmark case的扩展实现,case配置和容器环境的定制,芯片负载等信息采样脚本。
│ l── docker_image # 构建容器镜像所需文件,每个框架一个目录。
l── requirements.txt # FlagPerf依赖包
l── run_benchmarks # 启动训练任务的主体程序
│ l── config # 测试配置文件
│ l── # 每个框架一个目录,里面有启动对应框架任务的脚本start__task.py
│ l── prepare_in_container.py # 启动训练任务前初始化容器环境。
│ └── run.py # 启动和管理任务的脚本
└── utils # 测试任务管理的工具模块
以上,涉及新增框架的部分,主要是以下几个部分
- 镜像环境构建:/docker_image/
- 任务启动:run_benchmarks//start__task.py
- benchmark driver中对框架的支持:benchmarks/drivers/dist_.py
那么接下来,咱们就以添加tensorflow2为例,讲讲具体怎么做。示例中,对容器环境的准备,基于nvidia的GPU环境完成。
2. 自己动动手,新增框架
1) 支持镜像环境构建
FlagPerf对不同芯片的会自动构建构建不同的容器镜像,相关文件和脚本在/docker_image//下面,构建过程包括以下3个步骤:
- 第1步,使用Dockerfile构建基础镜像
- 第2步,启动容器加载基础镜像,执行_install.sh脚本
- 第3步,commit镜像并打tag
那么,要对nvida的GPU环境增加tensorflow2框架的支持,也很容易。
步骤如下:
- 创建对应的/docker_image/目录
# mkdir nvidia/docker_image/tensorflow2/- 创建并保存Dockerfile
# vim nvidia/docker_image/tensorflow2/Dockerfile
FROM nvcr.io/nvidia/tensorflow:21.10-tf2-py3
RUN apt-get update- 创建并保存 _install.sh脚本
# vim nvidia/docker_image/tensorflow2/tensorflow2_install.sh
#!/bin/bash
# Currently we have nothing to do when building docker image for tensorflow2至此,这一步就结束啦。等运行benchmark时,如有任务需要tensorflow2的框架,则FlagPerf会自动构建容器镜像。
如果想单独验证镜像环境的build,training/utils下有工具脚本:
- 使用FlagPerf的工具脚本构建镜像
# cd training/
# sudo python3 utils/image_manager.py -o build -i flagperf-nvidia-tensorflow2 -t t_v0.1 -d /home/flagopen/FlagPerf/training/nvidia/docker_image/tensorflow2/ -f tensorflow2- 使用docker images命令可以查看新做出来的镜像
# sudo docker images | grep tensorflow2 | grep flagperf
flagperf-nvidia-tensorflow2 t_v0.1 5f0bfe4c8490 20 seconds ago 14.5GB2) 支持训练任务准备和启动
FlagPerf启动训练任务时,需要先拉起一个容器加载第1)步构建的镜像。接下来就是在容器里做环境准备和启动任务了。
首先,环境准备阶段会调用run_benchmarks/prepare_in_container.py进行,这个脚本会安装/-/config/requirements.txt里指定的包,并调用/-/setup.py,编译安装/-/csrc下面的扩展包。至此,环境准备完毕。如果不需要额外的环境准备,可忽略这步。
然后是任务启动阶段,FlagPerf也提供了一些helper函数来实现这部分,参见training/utils/start_task_helper.py。新增框架的任务启动代码需放在run_benchmarks/里,这份代码里只需处理一些标准参数(比如vendor, model, framework, host_addr等),并根据标准参数信息,完成在一个容器内单张或多张异构卡的情况下启动模型训练脚本的工作。
由于TensorFlow框架分布式训练策略较多,所以我们这里考虑仅将集群信息、本节点IP和rank编号注入环境变量,具体的处理放在benchmark driver中实现一版通用方案。
3) 在benchmark driver中添加框架支持(可选)
driver目录地址位于training/benchmarks/driver,主要用于存放各个框架的分布式训练配置和通用工具包。我们现在以tensorflow为例,和大家简单介绍以下如何在driver中添加框架支持,具体细节大家可以多参读代码。
工具包部分的内容各个框架大概率可以复用,但分布式训练相关的设计终框架各有千秋,所以我们在driver里面针对各个框架有自己的分布式封装。
熟悉tensorflow2的同学一定知道,tf2的分布式方式可以以配置文件的形式指定,通过解析配置文件来初始化分布式策略,如下所示,假设我们在多机多卡的场景下配置为
runtime = dict(
distribution_strategy = 'multi_worker_mirrored',
run_eagerly = None,
tpu = None,
batchnorm_spatial_persistent = True)我们在training/benchmarks/driver/dist_tensorflow2.py中定configure_cluster方法来配置必要环境变量和get_distribution_strategy方法来初始化分布式策略。
在configure_cluster中,传入worker_hosts 和task_index 两个参数,构造最终的os.environ["TF_CONFIG"]变量。
在get_distribution_strategy方法中关键参数有:
- distribution_strategy: 指定分布式方式
- num_gpus:模型训练的卡数
- all_reduce_alg:指定all-reduce操作的算法
根据以上关键参数,在方法里做逻辑判断,初始化各项配置。
以上就是dist_tensorflow2.py 中的关键方法,其他需要的相关方法都可以放置于咱们的driver中。
3. 写个模型case,Enjoy it ~~
关于如何添加模型Case,咱们后续再细讲。为了方便快速验证,我们提供了一个生成dummy模型Case配置的工具,只需要执行utils/gen_dummy_benchmark.py脚本,给出厂商、框架名、配置模块名和数据目录几个参数,即可生成一个空的模型case配置,在容器中启动后可打印环境变量。
以TensorFlow2为例:
# python3 utils/gen_dummy_benchmark.py -v nvidia -f tensorflow2 -c config_A100x1x8 -d /home/datasets_ckpt/
You can run this command to clear dummy benchmark:
rm -rf /home/flagopen/github/FlagPerf/training/utils/../benchmarks/dummy/tensorflow2 /home/flagopen/github/FlagPerf/training/utils/../nvidia/dummy-tensorflow2/config /home/datasets_ckpt/
=======================================================
You can add the dummy benchmark case in test_conf like this:
DUMMY_TEST = {
"model": "dummy",
"framework": "tensorflow2",
"config": "config_A100x1x8",
"repeat": ,
"nnodes": ,
"nproc": ,
"data_dir_host": "/home/datasets_ckpt/",
"data_dir_container": "/mnt/data/dummy",
}可以按照提示将配置加入test_conf.py,就可以跑起来简单测试一下啦。你可以看到框架对应镜像的构建,容器启动、环境准备和dummy case的run_pretraining.py被启动执行并输出日志。
好啦,这样就完成一个框架的添加啦~ 接下来,我们要给FlagPerf添加benchmark的测试case啦,请听下回分解。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢