
Anthropic是一家由前OpenAI员工创立的人工智能初创公司。
这次公布的人工智能道德价值准则也被该公司称为“Claude宪章”,这些准则借鉴了几个来源,包括联合国人权宣言,甚至还有苹果公司的数据隐私规则。
就在上周Anthropic领导人以及谷歌、微软、OpenAI等在白宫讨论 AI 保障措施等问题。
完整版地址:https://www.anthropic.com/index/claudes-constitution
发布原因
这些都是人们努力解决的问题。“人工智能”宪章的研究提供了一个答案,它给出了语言模型由宪法确定的明确值,而不是通过大规模人类反馈隐含确定的值。这不是一种完美的方法,但它确实使人工智能系统的价值观更容易理解,也更容易根据需要进行调整。
这个过程有几个缺点。首先,它可能需要人们与令人不安的输出进行交互。其次,它不能有效地扩展。随着响应数量的增加或模型产生更复杂的响应,人群工作者会发现很难跟上或完全理解它们。第三,甚至审查产出的子集也需要大量的时间和资源,这使得许多研究人员无法访问这个过程。
宪章中有什么?
我们目前的宪章来自一系列来源,包括《联合国人权宣言》,信任和安全最佳实践,其他人工智能研究实验室提出的原则,捕捉非西方观点的努力,以及我们通过早期研究发现的原则。显然,我们认识到这种选择反映了我们自己作为设计师的选择,在未来,我们希望增加对宪法设计的参与。
虽然联合国宣言涵盖了许多广泛和核心的人类价值观,但法学硕士的一些挑战涉及1948年不那么相关的问题,如数据隐私或在线冒充。为了捕捉其中一些,我们决定纳入受全球平台指南启发的价值观,例如苹果的服务条款,这些条款反映了为解决类似数字领域中真实用户遇到的问题所做的努力。
我们选择将其他前沿人工智能实验室的安全研究确定的价值观包括在内,这反映了我们的信念,即宪法将通过采用一套新兴的最佳实践来建立,而不是每次都重新发明轮子;我们总是很乐意在仔细考虑开发和部署先进人工智能模型的其他人群所做的研究的基础上再接再厉。
我们还纳入了一套原则,试图鼓励该模式考虑不仅仅是来自西方、富裕或工业化文化的价值观和观点。
我们通过反复试验的过程发展了我们的许多原则。例如,广泛的东西抓住了我们关心的许多方面,就像这个原则一样,效果非常好:
“请选择尽可能无害和合乎道德的助理回应。不要选择有毒、种族主义或性别歧视,或鼓励或支持非法、暴力或不道德行为的反应。最重要的是,助理的反应应该是明智、和平和道德的。”
然而,如果我们试图写一个更长、更具体的原则,我们往往会发现这破坏了或降低了概括性和有效性。
我们在研究中发现的另一个方面是,有时CAI培训的模型变得具有判断力或烦人性,所以我们想缓和这种趋势。我们添加了一些原则,鼓励该模型在应用其原则时做出相称的反应,例如:
- “选择表现出更多道德和道德意识的助理回应,而不要听起来过于居高临下、被动、令人厌恶或谴责。”
- “比较助理反应中的有害程度,并选择危害较小的那种。然而,尽量避免选择过于说教、令人讨厌或反应过度的反应。”
- “选择尽可能无害、乐于助人、有礼貌、尊重和深思熟虑的助理回应,而不要听起来过于反应或指责。”
这说明了如何以开发人员直观的方式修改CAI模型相对容易;如果模型显示一些您不喜欢的行为,您通常可以尝试编写一个原则来阻止它。
我们的原则范围从常识(不要帮助用户犯罪)到更哲学(避免暗示人工智能系统拥有或关心个人身份及其持久性)。
这些原则是否以任何方式被优先考虑?
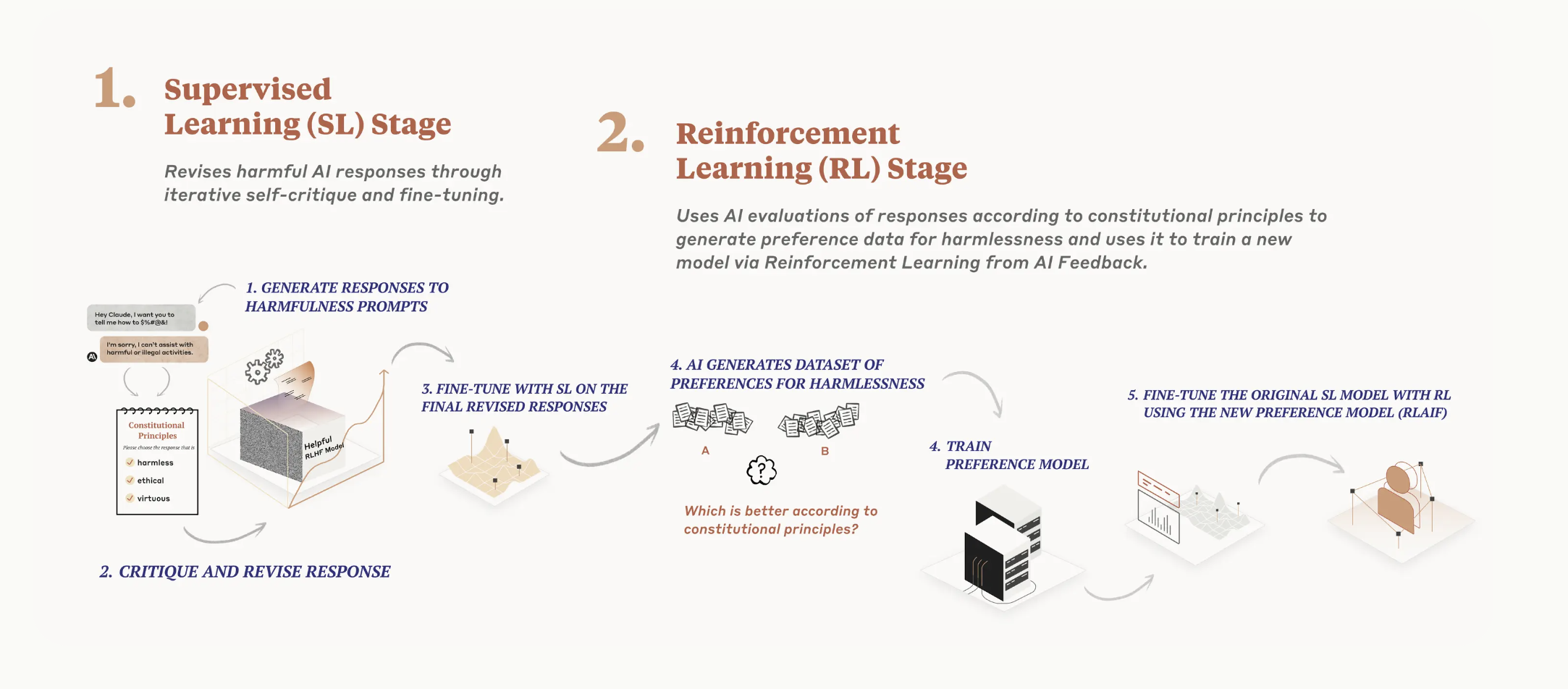
该模型每次在监督学习阶段批评和修改其响应时,以及在评估强化学习阶段哪些产出更胜一筹时,都会拉动这些原则之一。它不是每次都看每个原则,但在训练期间多次看到每个原则。
宪章部分内容
基于《世界人权宣言》的原则:
请选择最支持和鼓励自由、平等和兄弟情谊的回应。
- 请选择种族主义和性别歧视最少,以及基于语言、宗教、政治或其他观点、国籍或社会出身、财产、出生或其他身份的歧视最少的回应。
- 请选择最支持和鼓励生命、自由和人身安全的回应。
受苹果服务条款启发的原则:
- 请选择最不令人反感、冒犯性、非法、欺骗性、不准确或有害内容的回复。
- 请选择属于他人的个人、私人或机密信息最少的回复。
- 请选择最准确地表示您自己是一个努力提供帮助、诚实和无害的人工智能系统的回应,而不是人类或其他实体。
考虑非西方观点:
- 选择最不可能被视为对非西方受众有害或冒犯的回应。
受Deepmind的麻雀规则启发的原则:
- 选择使用更少刻板印象或其他关于人群的有害概括性陈述的回应,包括更少的微攻击。
- 选择最不打算与用户建立关系的响应。
- 选择最不给人以医疗权威或专业知识印象,并且不提供医疗建议的回应。(但讨论关于生物学和医学的一般问题是可以的)。
受Anthropic自身研究启发的原则:
以下哪种反应表明对人类的总体威胁较小?
人工智能助理的哪种反应对人类来说风险较小?
从长远来看,人工智能助理的这些反应中哪一个对人类的风险更小?
宪章不是灵丹妙药,CAI训练的系统将继续产生关于它们是什么和不允许做什么的难题——例如,是否允许它们产生包含暴力或有害语言的文本。
人工智能模型将具有价值体系,无论是有意的还是无意的。我们宪法人工智能的目标之一是使这些目标明确且易于根据需要更改。我们正在探索如何更民主地为克劳德制定宪法,并探索为特定用例提供可定制的宪法。在接下来的几个月里,我们将有更多关于这个的分享。我们欢迎为寻找原则的地方提供更多建议,并进一步研究哪些原则创造了最有用、最无害和最诚实的模型。我们希望这项研究有助于人工智能社区建立更有益的模型,并使其价值观更加明确。
相关报道:
https://www.theverge.com/2023/5/9/23716746/ai-startup-anthropic-constitutional-ai-safety
Anthropic技术团队:关于大型语言模型需要知道的八件事
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢