几何深度学习从对称性和不变性的角度解决较为广泛的ML 问题,为 CNN、GNN 和 Transformer 等神经网络架构提供了通用蓝图。在新完成的一系列文章中,我们研究了这些思想是如何将我们从古希腊转带到卷积神经网络的。

图片:Shutterstock。
在“迈向几何深度学习”系列的第三篇文章中,我们将讨论第一个“几何”神经网络模型:Neocognitron 和 CNN。这篇文章基于M. M. Bronstein,J. Bruna,T. Cohen和P. Veličković 合著的《Geometric Deep Learning》(完稿后将由麻省理工学院出版社出版)书的介绍章节,以及我们开设的非洲机器智能硕士(AMMI)课程内容。请参阅我们讨论对称性的第一篇文章,以及关于神经网络早期历史、“AI冬天”的第二篇文章。
新型“几何”类型的第一个神经网络架构,其灵感来自于神经科学。在一系列经典并带来诺贝尔医学奖的实验中,哈佛神经生理学家 David Hubel 和 Torsten Wiesel [1-2] 揭示了负责模式识别的大脑部分的结构和功能——视觉皮层。通过向猫展示不断变化的光模式并测量其脑细胞(神经元)的反应,他们表明视觉皮层中的神经元具有局部空间连接性的多层结构:只有当细胞在它附近区域(“感受野”[3])被激活。

诺贝尔奖获得者生理学家大卫·休贝尔和托斯滕·威塞尔及其经典实验的描述揭示了视觉皮层的结构。
此外,该组织似乎是分层的,其中“简单细胞”对局部原始定向阶梯状刺激的反应由“复杂细胞”聚合,从而产生对更复杂模式的反应。据推测,视觉皮层更深层的细胞会对由更简单的模式组成的日益复杂的模式做出反应,比如说,我们不妨半开玩笑般的假设存在一个“祖母细胞”,那这个细胞只有才显示出一个人的祖母的脸时才做出反应。
新认知机
对视觉皮层结构的理解,对计算机视觉和模式识别的早期作品产生了深远的影响,并多次尝试模仿其主要成分。当时日本广播公司的研究员 Kunihiko Fukushima 研发出一种新的神经网络架构 [5],“类似于 Hubel 和 Wiesel 提出的视觉神经系统的层次模型”,并被命名为neocognitron [6] 。
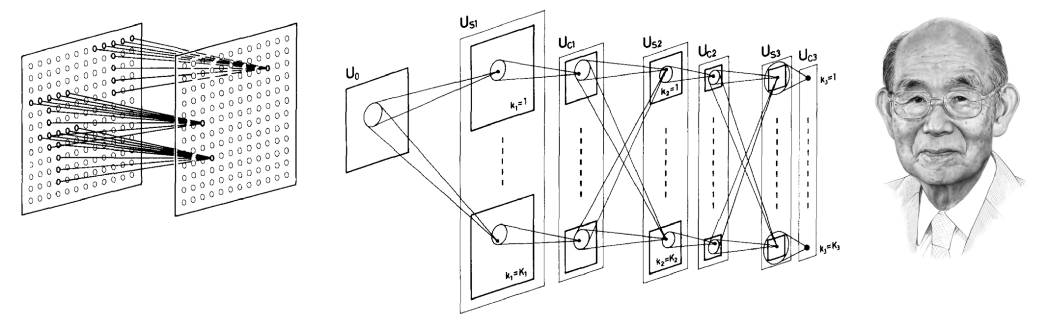
Kunihiko Fukushima 的neocognitron,是一种早期的几何深度学习架构,也是现代卷积神经网络的先驱。
新认知器由交错的S层和C 层组成神经元(反映其在生物视觉皮层中的灵感的命名约定);每一层的神经元按照输入图像的结构(“视网膜主题”)排列成二维阵列,每层有多个“细胞平面”(现代术语中的特征图)。S 层被设计为平移对称:它们使用共享的可学习权重聚合来自本地感受野的输入,从而导致单个细胞平面中的细胞具有相同功能的感受野,但在不同的位置。基本原理是选择可能出现在输入中任何位置的模式。C 层被固定并执行局部池化(加权平均),而对模式的特定位置不敏感:如果 C 神经元输入中的任何神经元被激活,则 C 神经元将被激活。
由于新认知器的主要应用是字符识别,因此翻译不变性 [7] 至关重要。这一特性与早期的神经网络(如 Rosenblatt 的感知器)有根本的区别:为了可靠地使用感知器,必须首先对输入模式的位置进行归一化,而在新认知器中,整个体系对模式位置并不敏感。Neocognitron 通过将翻译等值的局部特征提取层与池化交错来实现它,从而创建多尺度表示 [8]。计算实验表明,即使存在噪音和几何失真, Fukushima 的体系结构也能够成功识别复杂的图案,如字母或数字。
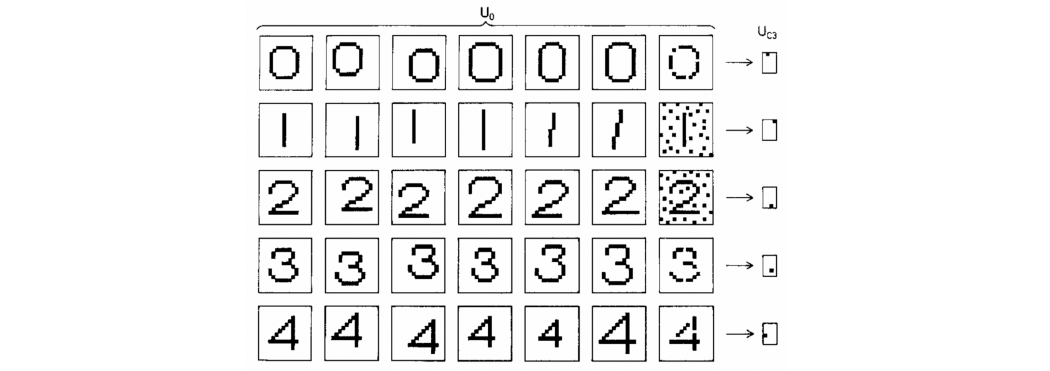
新认知器输出的例子证实了它对平移、几何失真和噪声不敏感。图片来自 [5]。
从该领域四个十年的进步来看,我们发现新认知器已经具有现代深度学习架构的许多惊人特征:深度(Fukishima 在他的论文中模拟了一个七层网络)、局部感受野、共享权重和池化。它甚至使用了半修正器 (ReLU) 激活函数,这通常被认为是在最近的深度学习架构中引入的 [9]。与现代系统的主要区别在于网络的训练方式:Neocognitron 是一种以无监督方式训练的“自组织”架构,因为反向传播尚未在神经网络社区中广泛使用。
卷积神经网络
Fukushima 的设计由巴黎大学 [10] 应届毕业生 Yann LeCun 做了进一步开发,他的博士论文是关于使用反向传播训练神经网络。在 AT&T 贝尔实验室的第一个博士后职位上,LeCun 和他的同事建立了一个系统来识别信封上的手写数字,以便让美国邮政局自动发送邮件。

Yann LeCun 和合著者 [11] 引入的第一个卷积神经网络(尽管稍后会出现“卷积”这个名称)。在 DSP 上实现,它允许实时手写数字识别。
在一篇已成为经典的论文 [11] 中,LeCun 等人描述了第一个三层卷积神经网络(CNN)[12]。与 neocognitron 类似,LeCun 的 CNN 也使用具有共享权重和池化的本地连接。然而,它放弃了 Fukushima 更复杂的非线性滤波(抑制性连接),取而代之的是简单的线性滤波器,这种滤波器可以使用数字信号处理器 (DSP) [13] 上的乘法和累加运算有效地实现卷积。这种设计选择,背离了神经科学的灵感和术语,进入了信号处理领域,将对深度学习的后续成功起到至关重要的作用。CNN 的另一个关键新颖之处是使用反向传播进行训练。
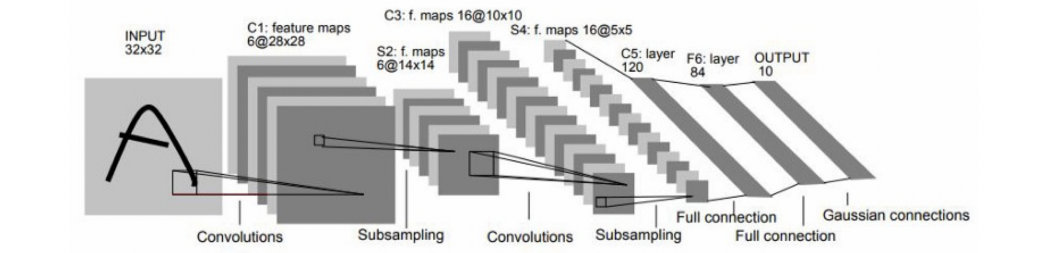
LeNet-5,一种五层卷积架构 [14]。
LeCun 的作品令人信服地展示了基于梯度的方法在复杂模式识别任务中的强大功能,并且是最早实用的基于深度学习的计算机视觉系统之一。这种架构的演变,一个有五层的 CNN,命名为 LeNet-5 作为作者名字的双关语 [14],被美国银行用来读取手写支票。
然而,当时计算机视觉研究界绝大多数人避开了神经网络,走上了不同的道路。在新千年头十年,视觉识别系统的典型架构是精心制作的特征提取器(通常检测图像中的兴趣点并以对透视变换和对比度变化具有鲁棒性的方式提供它们的局部描述[15 ])后跟一个简单的分类器(最常见的是支持向量机(SVM),更罕见的是小型神经网络)[16]。
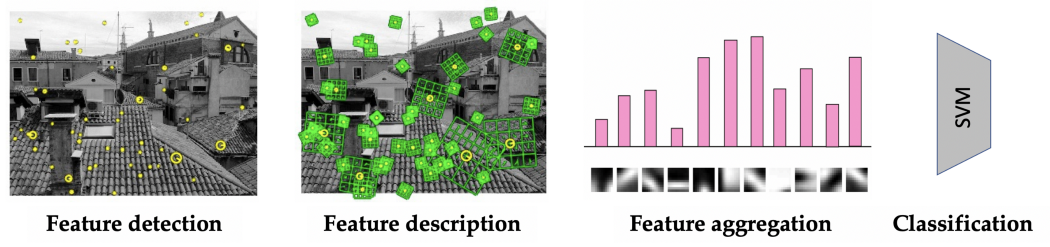
2000 年代 [16] 的典型“词袋”图像识别系统,由一个局部特征检测器和描述符组成,然后是一个简单的分类器。
深度学习的胜利
然而,计算能力的快速增长和可用注释视觉数据的数量改变了权力平衡。实现和训练越来越大、越来越复杂的 CNN 成为可能,从而可以解决越来越具有挑战性的视觉模式识别任务 [17],最终形成了当时计算机视觉的圣杯:ImageNet 大规模视觉识别挑战。ImageNet 由美籍华裔研究员李飞飞于 2009 年创立,是一项年度挑战,包括将数百万人类标记的图像分类为 1000 个不同类别。
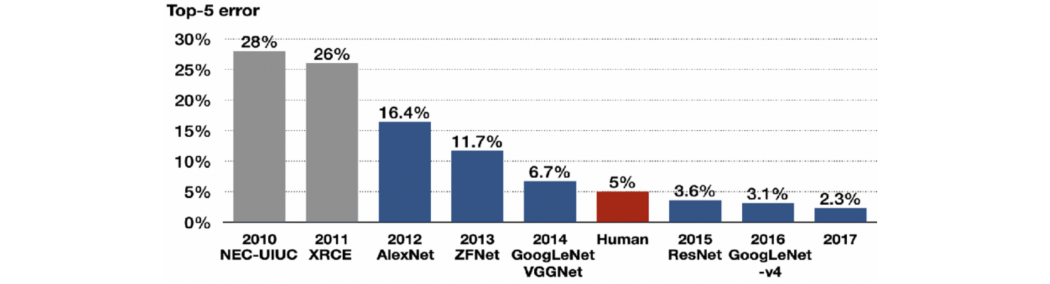
ImageNet 大规模视觉识别挑战赛的结果。2012 年,AlexNet 成为第一个击败“手工”方法的深度学习架构;从那时起,所有获胜的方法都是基于深度学习的。
由 Krizhevsky、Sutskever 和 Hinton [18] 在多伦多大学开发的 CNN 架构成功击败了所有竞争方法,例如有数十年研究积累、设计巧妙的特征检测器 [19]。在该领域数十年的研究中成功击败了所有竞争方法,例如智能设计的特征检测器 [19]。与其老兄弟 LeNet-5 [20] 相比,AlexNet(架构名为纪念开发者 Alex Krizhevsky 而命名)在参数和层数方面明显更大,但在概念上是相同的。关键区别在于,它使用图形处理器 (GPU) 进行训练 [21],现在是深度学习的主流硬件平台 [22]。
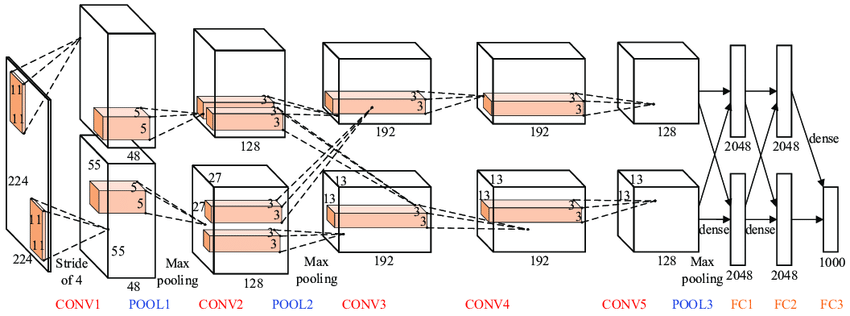
AlexNet 架构。图片:Bhavesh Singh Bisht。
CNN 在 ImageNet 上的成功成为深度学习的转折点,并预示着它在接下来的十年中被广泛接受。因此,价值数十亿美元的产业应运而生,深度学习成功地应用于商业系统,从苹果 iPhone 的语音识别到特斯拉的自动驾驶汽车。在对罗森布拉特的工作进行了严厉的审查四十多年后,联结主义者终于被证明是正确的。
参考文献:
[1] D. H. Hubel and T. N. Wiesel, Receptive fields of single neurones in the cat’s striate cortex (1959), The Journal of Physiology 148(3):574.
[2] D. H. Hubel and T. N. Wiesel, Receptive fields, binocular interaction and functional architecture in the cat’s visual cortex (1962), The Journal of Physiology 160(1):106.
[3] The term ‘receptive field’ predates Hubel and Wiesel and was used by neurophysiologists from the early twentieth century, see C. Sherrington, The integrative action of the nervous system (1906), Yale University Press.
[4] The term ‘grandmother cell’ is likely to have first appeared in Jerry Lettvin’s course ‘Biological Foundations for Perception and Knowledge’ held at MIT in 1969. A similar concept of ‘gnostic neurons’ was introduced two years earlier in a book by Polish neuroscientist J. Konorski, Integrative activity of the brain; an interdisciplinary approach (1967). See C. G. Gross, Genealogy of the “grandmother cell” (2002), The Neuroscientist 8(5):512–518.
[5] K. Fukushima, Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position (1980), Biological Cybernetics 36:196– 202. The shift-invariance property is alluded to in the title.
[6] Often misspelled as ‘neurocognitron’, the name ‘neocognitron’ suggests it was an improved version of an earlier architecture of K. Fukushima, Cognitron: a self-organizing multilayered neural network (1975), Biological Cybernetics 20:121–136.
[7] In the words of the author himself, having an output that is “dependent only upon the shape of the stimulus pattern, and is not affected by the position where the pattern is presented.”
[8] We refer to this principle as scale separation, which, like symmetry, is a fundamental property of many physical systems. In convolutional architectures, scale separation allows dealing with a broader class of geometric transformations in addition to translations.
[9] ReLU-type activations date back to at least the 1960s and have been previously employed in K. Fukushima, Visual feature extraction by a multilayered network of analog threshold elements (1969), IEEE Trans. Systems Science and Cybernetics 5(4):322–333.
[10] Université Pierre-et-Marie-Curie, today part of the Sorbonne University.
[11] Y. LeCun et al., Backpropagation applied to handwritten zip code recognition (1989) Neural Computation 1(4):541–551.
[12] In LeCun’s 1989 paper, the architecture was not named; the term ‘convolutional neural network’ or ‘convnet’ would appear in a later paper in 1998 [14].
[13] LeCun’s first CNN was trained on a CPU (a SUN-4/250 machine). However, the image recognition system using a trained CNN was run on AT&T DSP-32C (a second-generation digital signal processor with 256KB of memory capable of performing 125m floating-point multiply-and-accumulate operations per second with 32-bit precision), achieving over 30 classifications per second.
[14] Y. LeCun et al., Gradient-based learning applied to document recognition (1998), Proc. IEEE 86(11): 2278–2324.
[15] One of the most popular feature descriptors was the scale-invariant feature transform (SIFT), introduced by David Lowe in 1999. The paper was rejected multiple times and appeared only five years later, D. G. Lowe, Distinctive image features from scale-invariant keypoints, (2004) IJCV 60(2):91–110. It is one of the most cited computer vision papers.
[16] A prototypical approach was “bag-of-words” representing images as histograms of vector-quantised local descriptors. See e.g. J. Sivic and A. Zisserman, Video Google: A text retrieval approach to object matching in videos (2003), ICCV.
[17] In particular, the group of Jürgen Schmidhuber developed deep large-scale CNN models that won several vision competitions, including Chinese character recognition (D. C. Ciresan et al., Deep big simple neural nets for handwritten digit recognition (2010), Neural Computation 22(12):3207–3220) and traffic sign recognition (D. C. Ciresan et al., Multi-column deep neural network for traffic sign classification. Neural Networks 32:333–338, 2012).
[18] A. Krizhevsky, I. Sutskever, and G. E. Hinton, ImageNet classification with deep convolutional neural networks (2012), NIPS.
[19] AlexNet achieved an error over 10.8% smaller than the runner up.
[20] AlexNet had eleven layers was trained on 1.2M images from ImageNet (for comparison, LeNet-5 had five layers and was trained on 60K MNIST digits). Additional important changes compared to LeNet-5 were the use of ReLU activation (instead of tanh), maximum pooling, dropout regularisation, and data augmentation.
[21] It took nearly a week to train AlexNet on a pair of Nvidia GTX 580 GPUs, capable of ~200G FLOP/sec.
[22] Though GPUs were initially designed for graphics applications, they turned out to be a convenient hardware platform for general-purpose computations (“GPGPU”). First such works showed linear algebra algorithms, see e.g. J. Krüger and R. Westermann, Linear algebra operators for GPU implementation of numerical algorithms (2003), ACM Trans. Graphics 22(3):908–916. The first use of GPUs for neural networks was by K.-S. Oh and K. Jung, GPU implementation of neural networks (2004), Pattern Recognition 37(6):1311–1314, predating AlexNet by nearly a decade.
The portrait of Fukushima was hand-drawn by Ihor Gorskiy. Detailed lecture materials on Geometric Deep Learning are available on the project webpage. See Michael’s other posts in Towards Data Science, subscribe to his posts, get Medium membership, or follow Michael, Joan, Taco, and Petar on Twitter.
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢