
关于周刊:
关于周刊订阅:
告诉大家一个好消息,《强化学习周刊》开启“订阅功能”,以后我们会向您自动推送最新版的《强化学习周刊》。订阅方法:
1,注册智源社区账号
2,点击周刊界面左上角的作者栏部分“强化学习周刊”(如下图),进入“强化学习周刊”主页。

3,点击“关注TA”(如下图)
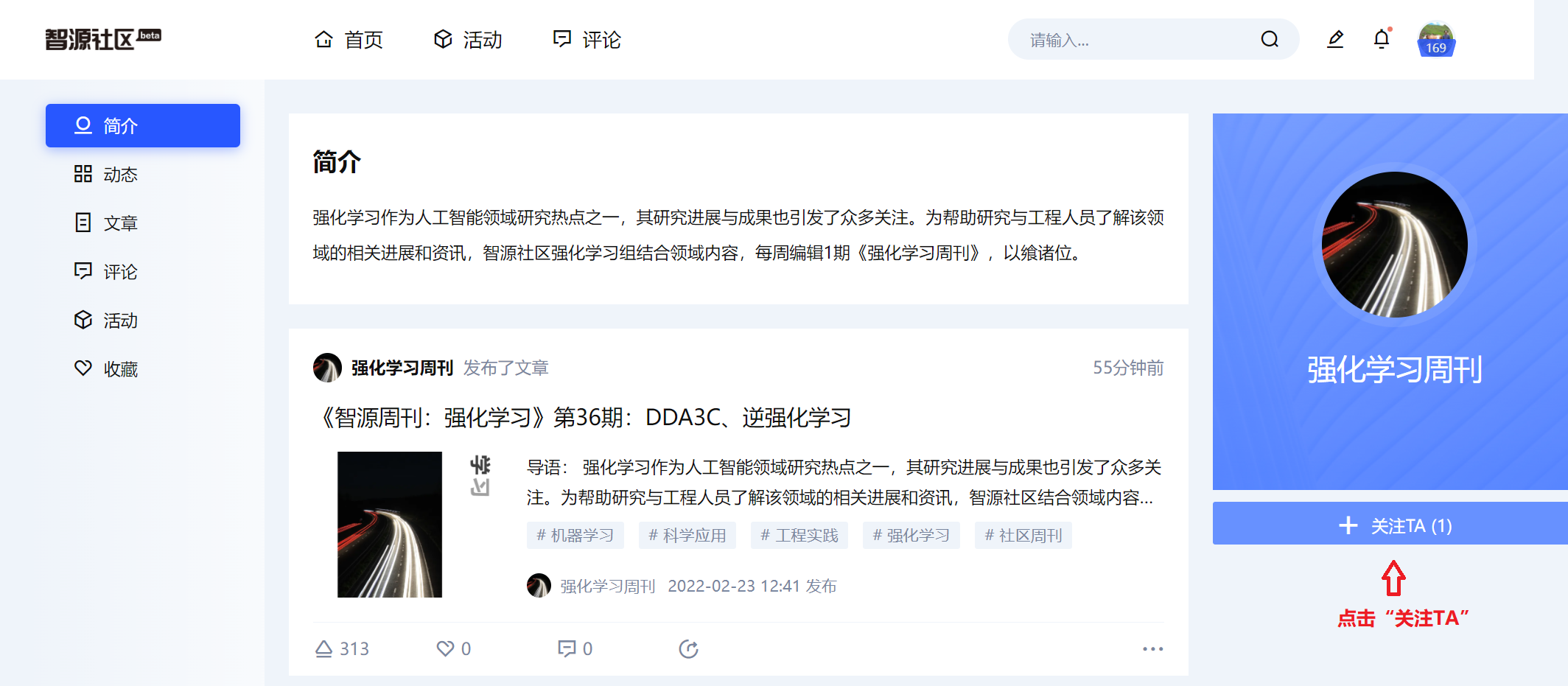
4,您已经完成《强化学习周刊》订阅啦,以后智源社区会自动向您推送最新版的《强化学习周刊》!
导语:
强化学习作为人工智能领域研究热点之一,其在人工智能领域以及学科交叉研究中的突出表现,引起越来越多的研究人员对该领域的关注。为更好地服务相关研究人员及时了解强化学习领域的研究进展以及科研资讯,智源社区结合以前工作基础及读者反馈,在论文推荐基础之上新增科研资讯、学术讲座、强化学习教程、相关招聘等板块,撰写为第70期《强化学习周刊》以飨诸位。
周刊采用社区协作的模式产生,欢迎感兴趣的朋友们参与我们的工作,一起来推动强化学习社群的分享、学习和交流活动。社区将定期为推动强化学习社群建设表现优异的同学提供精美的奖品。可以扫描文末的二维码加入强化学习社区群。
本期贡献者:(李明,刘青、小胖)
导读
强化学习已经成为人工智能研究领域的热点,其在各个应用领域中取得了瞩目的成就。《强化学习周刊》共分四个板块,本周论文推荐板块为读者梳理了CVPR 2022的8篇强化学习相关研究论文,其中涉及到弹道分布预测、基于异步视听集成查找坠落物体、基于神经二分图匹配的多机器人主动映射等;科研资讯为读者分享来自DeepMind 推出 DeepNash攻克西洋陆军棋游戏,DeepMind 团队介绍了 DeepNash 这一自主智能体,利用博弈论、无模型的深度强化学习方法,无需搜索,通过从头开始的自我对弈来学习掌握 Stratego;招聘版块为大家介绍来自腾讯的招聘:TEG-强化学习算法研究员(游戏AI);教程推荐板块为大家分享来自 加州大学伯克利分校 CS 285 深度强化学习课程,本课程是加州大学伯克利分校在2022年秋季学期开设的深度强化学习课程,本课程适合对强化学习有一定了解,想要进一步深入学习深度强化学习的朋友。
论文推荐
CVPR 2022是人工智能和机器学习领域的全球顶级学术会议。2022年6月19日至24日,CVPR2022在美国路易斯安那州新奥尔良举行。
标题:End-to-End Trajectory Distribution Prediction Based on Occupancy Grid Maps(香港大学: Ke Guo | 基于占用网格图的端到端弹道分布预测)
简介:本文的目标是在给定社会场景图像和历史轨迹的情况下,预测现实世界中移动代理的未来轨迹分布。然而,这是一项具有挑战性的任务,因为地面真实分布是未知和不可观测的,而只有一个样本可以用于监督模型学习,这很容易产生偏差。最新的研究集中在预测不同的轨迹,以涵盖真实分布的所有模式,但他们可能会轻视精度,从而对不切实际的预测给予过多的赞誉。为此,通过使用占用网格图来学习具有对称交叉熵的分布,作为地面真实分布的显式和符合场景的近似,这可以有效地惩罚不可能的预测。基于逆强化学习的多模态轨迹分布预测框架,该框架通过近似值迭代网络以端到端的方式学习规划。此外,基于预测的分布,通过基于可微Transformer的网络生成一小组代表性轨迹,其注意力机制有助于建模轨迹之间的关系。在实验中,该方法在斯坦福无人机数据集和交集无人机数据集中实现了最先进的性能。
论文链接:https://arxiv.org/pdf/2203.16910.pdf
阅读详情
标题:IntraQ: Learning Synthetic Images with Intra-Class Heterogeneity for Zero-Shot Network Quantization(厦门大学 : Yunshan Zhong | IntraQ:学习具有类内异质性的合成图像用于零样本网络量化)
简介:学习合成数据已成为零样本量化(ZSQ)的一个有前景的研究方向,它通过低位整数表示神经网络,而无需访问任何真实数据。本文观察到真实数据中类内异质性的有趣现象,并表明现有方法无法在其合成图像中保留这一特性,这导致了有限的性能提高。其提出了新的零样本量化方法,称为IntraQ。首先,通过局部对象增强方法,在合成图像的不同尺度和位置定位目标对象。其次,引入边缘距离约束来形成分布在粗糙区域中的类相关特征。最后,设计了一个软初始损失,它注入了软先验标记,以防止合成图像过度拟合到固定对象。IntraQ被证明很好地保留了合成图像中的类内异质性,并且观察到表现最先进。例如,与先进的ZSQ相比,当MobileNetV1的所有层量化为4位时,IntraQ在ImageNet上获得了9.17%的前MobileNetV1精度。
论文链接:https://arxiv.org/pdf/2111.09136v5.pdf
阅读详情
标题:Finding Fallen Objects Via Asynchronous Audio-Visual Integration(MIT and MIT-IBM Watson AI Lab : Chuang Gan | 基于异步视听集成查找坠落物体)
简介:物体的外观和声音提供了其物理特性的互补反映。在许多情况下,视觉和听觉的线索是异步到达的,但必须整合在一起,就像我们听到一个物体掉在地板上,然后必须找到它一样。本文介绍了研究三维虚拟环境中多模态对象定位的设置。一个物体掉在房间的某处。一个配备了摄像头和麦克风的机器人特工必须通过结合音频和视频信号以及基础物理知识来确定什么物体落下了——以及落在哪里。为了研究这个问题,本文生成了大型数据集——坠落物体数据集——其中包括64个房间中30个物理物体类别的8000个实例。该数据集使用ThreeDWorld平台,该平台可以模拟基于物理的撞击声和真实感场景中对象之间的复杂物理交互。作为解决这一挑战的第一步,基于模仿学习、强化学习和模块化规划开发了一组具体化的代理基线,并对这一新任务的挑战进行了深入分析。
论文链接:https://arxiv.org/pdf/2207.03483.pdf
阅读详情
标题:Reinforced Structured State-Evolution for Vision-Language Navigation(Beihang University:Jinyu Chen | 视觉语言导航的强化结构化状态演化)
简介:视觉和语言导航(VLN)任务要求具体化的代理按照自然语言指令导航到远程位置。先前的方法通常采用序列模型(例如Transformer和LSTM)作为导航器。在这样的范例中,序列模型通过保持的导航状态预测每一步的动作,导航状态通常表示为一维向量。然而,由于所维护的向量基本上是非结构化的,因此对于具体导航任务的关键导航线索(即,对象级环境布局)被丢弃。本文提出了一种新的结构化状态演化(SEvol)模型,以有效地维护VLN的环境布局线索,使用基于图形的特征来表示导航状态,而不是基于向量的状态。因此,设计了一个强化布局线索挖掘器(RLM),通过定制的强化学习策略挖掘和检测用于长期导航的最关键的布局图。此外,提出了结构化演化模块(SEM)以在导航期间保持基于结构化图的状态,其中状态被逐渐演化以学习对象级时空关系。在R2R和R4R数据集上的实验表明,所提出的SEvol模型通过大幅度提高了VLN模型的性能,例如,在R2R测试集上,NvEM的SPL绝对精度为+3%,EnvDrop的SPL精度为+8%。
论文链接:https://arxiv.org/pdf/2204.09280v2.pdf
阅读详情
标题:Bailando: 3D Dance Generation by Actor-Critic GPT with Choreographic Memory(南洋理工大学: Li Siyao|Bailando:具有编舞记忆的演员-评论家 GPT 的 3D 舞蹈生成)
简介:由于编舞规范对姿势施加的空间限制,驱动3D角色跟随音乐跳舞极具挑战性。 此外,生成的舞蹈序列还需要与不同的音乐流派保持时间一致性。 为了应对这些挑战,本文提出了一个新颖的音乐到舞蹈框架 Bailando,它具有两个强大的组件:1) 舞蹈记忆,它学习从 3D 姿势序列到量化代码,来总结有意义的舞蹈单元,2) 演员评论家 Generative Pre-trained Transformer (GPT) ,它将这些单元组合成与音乐连贯的流畅舞蹈。为了实现不同运动节奏和音乐节拍之间的同步对齐,作者向 GPT 引入了一种基于演员-评论家的强化学习方案,并具有新设计的节拍对齐奖励功能。 在标准基准上进行的大量实验表明,本文提出的框架在定性和定量上都达到了最先进的性能。值得注意的是,学习到的编舞记忆被证明能够以无人监督的方式发现人类可解释的舞蹈风格姿势。
论文链接:https://arxiv.org/pdf/2203.13055.pdf
阅读详情
标题:Coarse-to-Fine Q-attention: Efficient Learning for Visual Robotic Manipulation via Discretisation(伦敦帝国学院: Stephen James|从粗略到精细的Q-attention:通过离散化实现视觉机器人操作的有效学习)
简介:本文提出了一种从粗到细的离散化方法,该方法能够在连续机器人领域中使用离散强化学习方法来代替不稳定和数据效率低下的行为体批判方法。这种方法建立在最近发布的ARM算法的基础上,该算法将连续的次优姿态智能体替换为离散的,具有从粗到细的Q-attention。给定一个体素化的场景,从粗到细的Q-attention会学习要“放大”场景的哪个部分。当这种“缩放”行为被迭代应用时,它会导致平移空间的近似无损离散化,并允许使用离散动作、深度Q学习方法。实验表明,本文的新算法从粗到精在几个困难的、报酬很少的基于RLBench视觉的机器人任务上实现了最先进的性能,并且可以在几分钟内训练真实世界的策略,只需3次演示。
论文链接:https://arxiv.org/pdf/2106.12534.pdf
阅读详情
标题:Good, Better, Best: Textual Distractors Generation for Multiple-Choice Visual Question Answering via Reinforcement Learning(亚利桑那州立大学: Jiaying Lu|好,更好,最好:通过强化学习为多选 VQA 生成文本干扰因素)
简介:随着自动构建大规模多选题VQA数据的需求的增长,本文引入了一个新的任务,称为VQA的文本干扰因素生成(DG-VQA),DG-VQA任务的目的是在没有地面真实训练样本的情况下生成干扰因素,因为这种资源很少。为了在无监督的情况下处理DG-VQA,本文提出了GOBBET,这是一个基于强化学习(RL)的框架,利用预先训练好的VQA模型作为替代知识库来指导干扰源的生成过程。在GOBBET中,预训练的VQA模型作为RL环境,为输入的多模态查询提供反馈,而神经分心器生成器则作为智能体,采取相应行动。本文建议使用现有的VQA模型的性能下降作为生成的分心物的质量指标。另一方面,文中通过数据增强实验展示了生成的分心器的效用,因为当人工智能模型应用于不可预测的开放领域场景或安全敏感的应用时,鲁棒性越来越重要。
论文链接:https://arxiv.org/pdf/1910.09134.pdf
阅读详情
标题:Multi-Robot Active Mapping via Neural Bipartite Graph Matching(北京大学: Kai Ye|基于神经二分图匹配的多机器人主动映射)
简介:本文研究了多机器人主动映射问题,其目标是在最短的时间内完成场景地图的构建。这个问题的关键在于目标位置估计,以实现更有效的机器人运动。以前的方法要么通过阻碍时间效率的短视解决方案选择边界作为目标位置,要么通过强化学习直接回归目标位置来最大化长期价值,但不能保证完整的地图构建。本文提出了一种新的算法,即NeuralCoMapping, 它利用了这两种方法。本文将问题简化为二分图匹配,它建立了两个图之间的节点对应关系,表示机器人和边界。文中引入了一个多路图神经网络 (mGNN),它学习神经距离以填充亲和矩阵,从而实现更有效的图匹配。并且通过强化学习最大化有利于时间效率和地图完整性的长期值,使用可微分线性分配层优化 mGNN。实验结果表明此算法在各种室内场景和未知数量的机器人上具有卓越的性能和出色的泛化能力。
论文链接:https://arxiv.org/pdf/2203.16319.pdf
阅读详情
科研资讯
标题:DeepMind 推出 DeepNash攻克西洋陆军棋游戏
简介:近期,Science上发表了DeepMind的一篇AI玩转西洋陆军棋(Stratego)的论文,引发关注。Stratego是一种不完全信息博弈,需要像国际象棋一样的长期战略思考,但它也需要像打扑克一样处理不完美的信息,因此是人工智能 (AI) 尚未掌握的少数标志性棋盘游戏之一。DeepMind 团队介绍了 DeepNash 这一自主智能体,利用博弈论、无模型的深度强化学习方法,无需搜索,通过从头开始的自我对弈来学习掌握 Stratego。DeepNash成功地展示了,AI如何在不确定的情况下,完美地平衡了结果,解决了复杂的问题。DeepNash 在 Stratego 中击败了现有的最先进的 AI 方法,并在世界上最大的Stratego平台 Gravon 的人类专家中取得了年初至今(2022 年)和历史前三的排名。
资讯链接:https://www.science.org/doi/epdf/10.1126/science.add4679
阅读详情
相关招聘
标题:腾讯招聘:TEG-强化学习算法研究员(游戏AI)
工作职责:负责腾讯游戏AI的算法研究和应用,包括但不限于强化学习、模仿学习、元学习等;
负责设计新的强化学习算法,提高强化学习效率和效果,并结合腾讯游戏应用场景,提供技术解决方案;
负责前沿技术的探索,推进强化学习在更多业务场景的应用。
工作要求:计算机相关专业,硕士及以上学历,3年以上相关工作经验;对机器学习、强化学习、深度学习、最优化理论等算法原理及其在互联网行业的应用有深入的理解和浓厚的兴趣,在NeurIPS、ICML、ICLR、AAAI等顶会发表论文者优先;基础扎实,编码过关,熟悉常用的算法和数据结构,熟练掌握C/C++、Java、Python等至少一门编程语言,有熟悉k8s等容器相关技术、大规模DeepLearning系统研发经验者优先;具备较强动手和快速学习能力,能够应用TF、PyTorch等主流框架实现模型搭建与算法调优。
招聘链接:https://careers.tencent.com/jobdesc.html?postId=1536993162751385600
阅读详情
教程推荐
标题:加州大学伯克利分校 CS 285 深度强化学习课程
简介:本课程是加州大学伯克利分校在2022年秋季学期开设的深度强化学习课程,本课程需要前置课程CS189,并且将假定您熟悉强化学习、数值优化和机器学习,适合对强化学习有一定了解,想要进一步深入学习深度强化学习的朋友。课程提供全程的教学录像和幻灯片,可以在网站内按需观看和下载。
教程链接:http://rail.eecs.berkeley.edu/deeprlcourse/
阅读详情
如果你正在从事或关注强化学习研究、实现与应用,欢迎加入“智源社区-强化学习-交流群”。在这里,你可以:
学习前沿知识、求解疑难困惑
分享经验心得、展示风貌才华
参与专属活动、结识研究伙伴
请扫描下方二维码加入。 备注:“姓名+单位+强化学习”才会验证进群哦。

内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢