
在昨天的GTC 2023上,黄仁勋发布了四款AI推理芯片,包括针对生成式AI图像处理、大模型处理的芯片;发布了三个大模型云服务,分别适用于文本、图像和生物研究;发布了超级计算机,以及针对场景优化的应用100个、更新功能的工业元宇宙Omniverse。
NVIDIA 近日宣布推出H100 NVL - 用于大型语言模型的最大内存服务器卡
训练大型语言模型(LLM)的GPU——H100 NVL
2022年的GTC上,英伟达带来了全新GPU架构NVIDIA Hopper,同时推出了首个基于Hopper架构打造的产品NVIDIA H100。一年的时间里,H100已经成为各大科技训练人工智能模型使用最多的GPU之一。
在此次GTC 2023上,黄仁勋推出了一个巨大的专门用于训练大型语言模型(LLM)的GPU——H100 NVL。
这是一个基于去年英伟达发布的H100的改进版本,它将两个H100 GPU通过NVLink拼接在一起,支持188 GB HBM3内存。卡名称中的“NVL”代表 NVLink,它通过外部接口(桥接器)以600 GB/s的速度连接两张H100。但实际上如果在技术条件允许的前提下,通过NVLink协议可以将至多256 个H100连接在一起。
这不是一个消费级的GPU产品,H100 NVL是为了服务于大型语言模型,这个专用的GPU计划于下半年推出。
大模型对内存和计算方面的需求较高,也需要很高容量的横向扩展能力。目前,能够处理拥有1750 亿参数的 GPT-3 等大型语言模型的只有A100,而GPT-4等参数量更大的模型则需要更多A100的堆叠。性能方面,一台8卡的H100 NVL的速度是目前标配8卡A100服务器的10倍。这不仅意味着速度的提升,也将降低大模型公司在算力方面的成本。

原文地址
虽然今年的春季 GTC 活动没有采用 NVIDIA 的任何新 GPU 或 GPU 架构,但该公司仍在推出基于去年推出的 Hopper 和 Ada Lovelace GPU 的新产品。在高端市场,该公司近日宣布推出专门针对大型语言模型用户的新 H100 加速器变体:H100 NVL。
H100 NVL 是NVIDIA H100 PCIe 卡的一个有趣变体,标志着时代和NVIDIA在人工智能领域的广泛成功,它针对一个特定市场:大型语言模型(LLM)部署。这张卡片与NVIDIA通常的服务器产品有一些不同之处——最显著的是它是两个H100 PCIe板卡的组合——但是最大的卖点就是它拥有巨大的内存容量。这个结合了双GPU的卡提供了188GB的HBM3内存,每张卡片为94GB,每个GPU的内存超过了迄今为止的任何其他NVIDIA产品,甚至比H100系列内的其他产品还多。
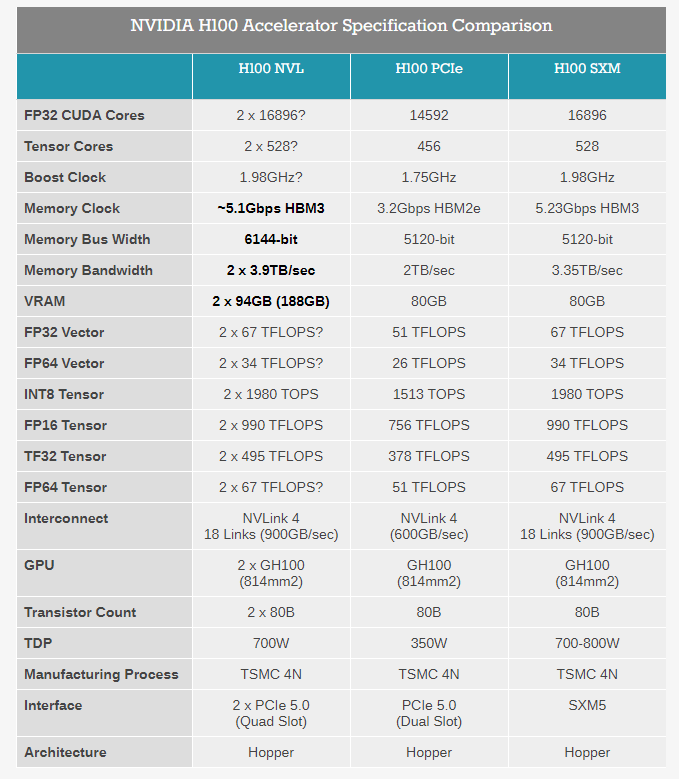
驱动此 SKU 的是一个特定的利基市场:内存容量。像 GPT 系列这样的大型语言模型在许多方面都受到内存容量的限制,因为它们甚至会很快填满 H100 加速器以保存它们的所有参数(在最大的 GPT-3 模型的情况下为 175B)。因此,NVIDIA 选择拼凑出一个新的 H100 SKU,它为每个 GPU 提供的内存比他们通常的 H100 部件多一点,后者最高为每个 GPU 80GB。
在引擎盖下,我们看到的本质上是放置在 PCIe 卡上的GH100 GPU的特殊容器。所有 GH100 GPU 都配备 6 个 HBM 内存堆栈(HBM2e 或 HBM3),每个堆栈的容量为 16GB。然而,出于产量原因,NVIDIA 仅在其常规 H100 部件中提供 6 个 HBM 堆栈中的 5 个。因此,虽然每个 GPU 上标称有 96GB 的 VRAM,但常规 SKU 上只有 80GB 可用。

反过来,H100 NVL 是神话般的完全启用的 SKU,启用了所有 6 个堆栈。通过打开第 6个HBM 堆栈,NVIDIA 能够访问它提供的额外内存和额外内存带宽。它将对产量产生一些实质性影响——多少是 NVIDIA 严密保守的秘密——但 LLM 市场显然足够大,并且愿意为近乎完美的 GH100 封装支付足够高的溢价,以使其值得 NVIDIA 光顾。
即便如此,应该注意的是,客户无法访问每张卡的全部 96GB。相反,在总容量为 188GB 的内存中,它们每张卡的有效容量为 94GB。在今天的主题演讲之前,NVIDIA 没有在我们的预简报中详细介绍这个设计怪癖,但我们怀疑这也是出于产量原因,让 NVIDIA 在禁用 HBM3 内存堆栈中的坏单元(或层)方面有一些松懈。最终结果是新 SKU 为每个 GH100 GPU 提供了 14GB 的内存,内存增加了 17.5%。同时,该卡的总内存带宽为 7.8TB/秒,单个板的总内存带宽为 3.9TB/秒。
除了内存容量增加之外,更大的双 GPU/双卡 H100 NVL 中的各个卡在很多方面看起来很像放置在 PCIe 卡上的 H100 的 SXM5 版本。虽然普通的 H100 PCIe 由于使用较慢的 HBM2e 内存、较少的活动 SM/张量核心和较低的时钟速度而受到一些限制,但 NVIDIA 为 H100 NVL 引用的张量核心性能数据与 H100 SXM5 完全相同,这表明该卡没有像普通 PCIe 卡那样进一步缩减。我们仍在等待产品的最终、完整规格,但假设这里的所有内容都如所呈现的那样,那么进入 H100 NVL 的 GH100 将代表当前可用的最高分档 GH100。

这里需要强调复数。如前所述,H100 NVL 不是单个 GPU 部件,而是双 GPU/双卡部件,它以这种方式呈现给主机系统。硬件本身基于两个 PCIe 外形规格的 H100,它们使用三个 NVLink 4 桥接在一起。从物理上讲,这实际上与 NVIDIA 现有的 H100 PCIe 设计完全相同——后者已经可以使用 NVLink 桥接器进行配对——所以区别不在于两板/四插槽庞然大物的结构,而是内部硅的质量。换句话说,您今天可以将普通的 H100 PCIe 卡捆绑在一起,但它无法与 H100 NVL 的内存带宽、内存容量或张量吞吐量相匹配。
令人惊讶的是,尽管有出色的规格,但 TDP 几乎保持不变。H100 NVL 是一个 700W 到 800W 的部件,分解为每块板 350W 到 400W,其下限与常规 H100 PCIe 的 TDP 相同。在这种情况下,NVIDIA 似乎将兼容性置于峰值性能之上,因为很少有服务器机箱可以处理超过 350W 的 PCIe 卡(超过 400W 的更少),这意味着 TDP 需要保持稳定。不过,考虑到更高的性能数据和内存带宽,目前还不清楚 NVIDIA 如何提供额外的性能。Power binning 在这里可以发挥很大的作用,但也可能是 NVIDIA 为卡提供比平常更高的提升时钟速度的情况,因为目标市场主要关注张量性能并且不会点亮整个 GPU一次。
否则,鉴于 NVIDIA 对 SXM 部件的普遍偏好,NVIDIA 决定发布本质上最好的 H100 bin 是一个不寻常的选择,但在 LLM 客户的需求背景下,这是一个有意义的决定。基于 SXM 的大型 H100 集群可以轻松扩展到 8 个 GPU,但任何两个 GPU 之间可用的 NVLink 带宽量因需要通过 NVSwitch 而受到限制。对于只有两个 GPU 的配置,将一组 PCIe 卡配对要直接得多,固定链路保证卡之间的带宽为 600GB/秒。
但也许比这更重要的是能够在现有基础设施中快速部署 H100 NVL。LLM 客户无需安装专门为配对 GPU 而构建的 H100 HGX 载板,只需将 H100 NVL 添加到新的服务器构建中,或者作为对现有服务器构建的相对快速升级即可。毕竟,NVIDIA 在这里针对的是一个非常特殊的市场,因此 SXM 的正常优势(以及 NVIDIA 发挥其集体影响力的能力)可能不适用于此。
综上所述,NVIDIA宣传H100 NVL提供的推理吞吐量是上一代HGX A100的12倍(8颗H100 NVL与8颗A100相比的GPT3-175B推理吞吐量)。对于希望尽快部署和扩展他们的系统以适应LLM工作负载的客户来说,这将是非常吸引人的。如前所述,就架构特性而言,H100 NVL并没有带来任何新的东西——其性能提升的很大一部分来自Hopper架构中的新Transformer引擎。但是,H100 NVL将在一个特定的领域发挥作用,因为它是最快的PCIe H100选项,并拥有最大的GPU内存池。
总的来说,据NVIDIA表示,H100 NVL卡将在今年下半年开始出货。公司没有公布价格,但由于它基本上是一款最高GH100级别的产品,我们预计它们的价格会很高。特别是随着LLM使用的爆炸式增长,这正成为服务器GPU市场的新热门,更增加了它们的高价值。
参考链接:
【1】原文链接:
【2】https://hub.baai.ac.cn/view/24983
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢