
关于周刊
本期周刊,我们选择了8篇预训练相关的论文,涉及文本长度泛化、用户表征、文本生成、多模态、图像生成、机器人导航多模态、多模态测评和分子表征的探索。此外,在研究动态方面,我们选择了3篇预训练资讯,将介绍多语言模型、模型自我审视和RNA基础模型方面的一些最新内容。
周刊采用社区协作的模式产生,欢迎感兴趣的朋友们参与我们的工作,一起来推动预训练学习社群的分享、学习和交流活动。可以扫描文末的二维码加入预训练群。
(本期贡献者:申德周 翟珂 吴新刚)
关于周刊订阅
告诉大家一个好消息,《预训练周刊》开启“订阅功能”,以后我们会向您自动推送最新版的《预训练周刊》。订阅方法:
方式一:
扫描下面二维码,进入《预训练周刊》主页,选择“关注TA”。

方式二:
1,注册智源社区账号
2,点击周刊界面左上角的作者栏部分“预训练周刊”(如下图),进入“预训练周刊”主页。
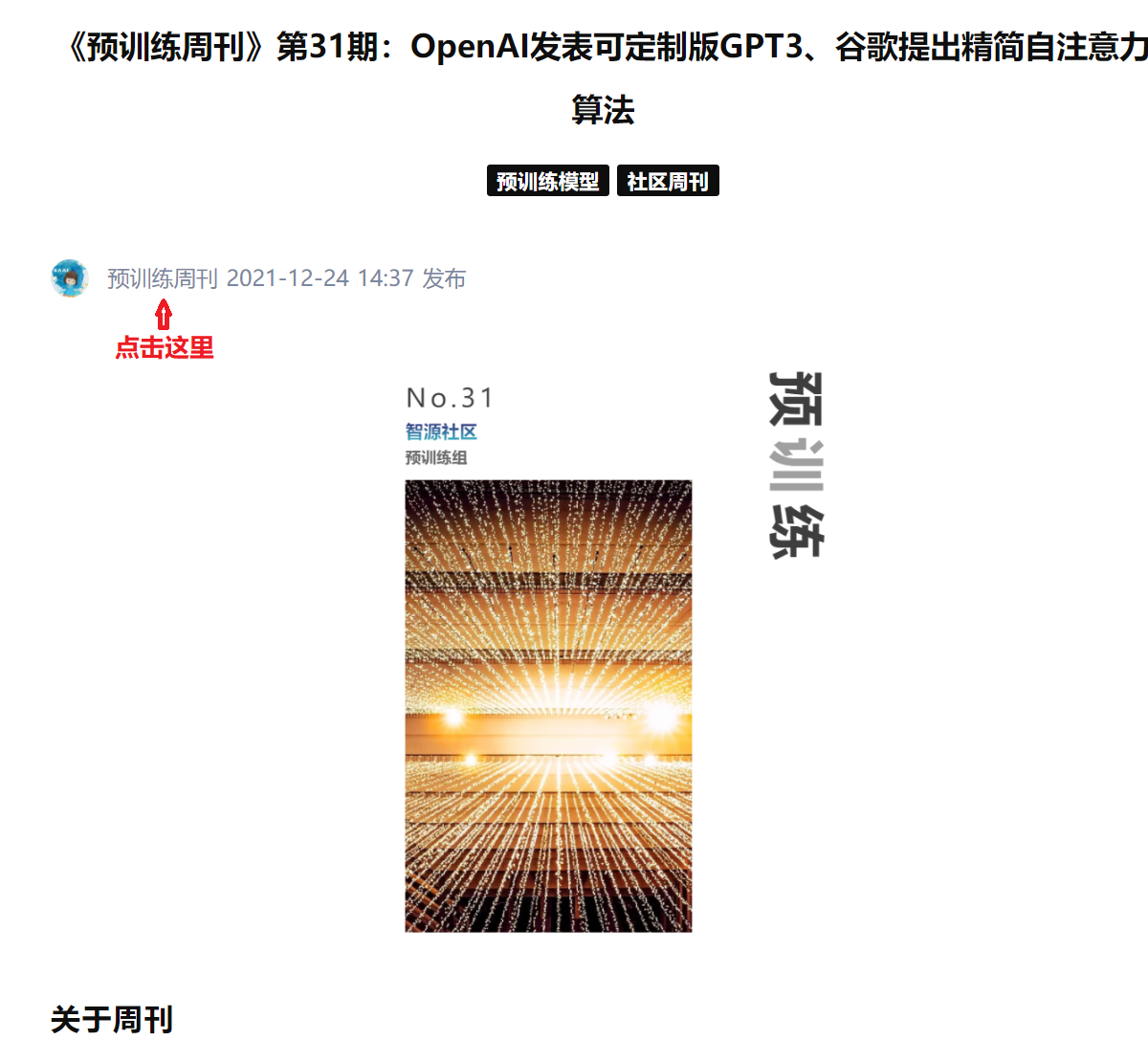
3,点击“关注TA”(如下图)
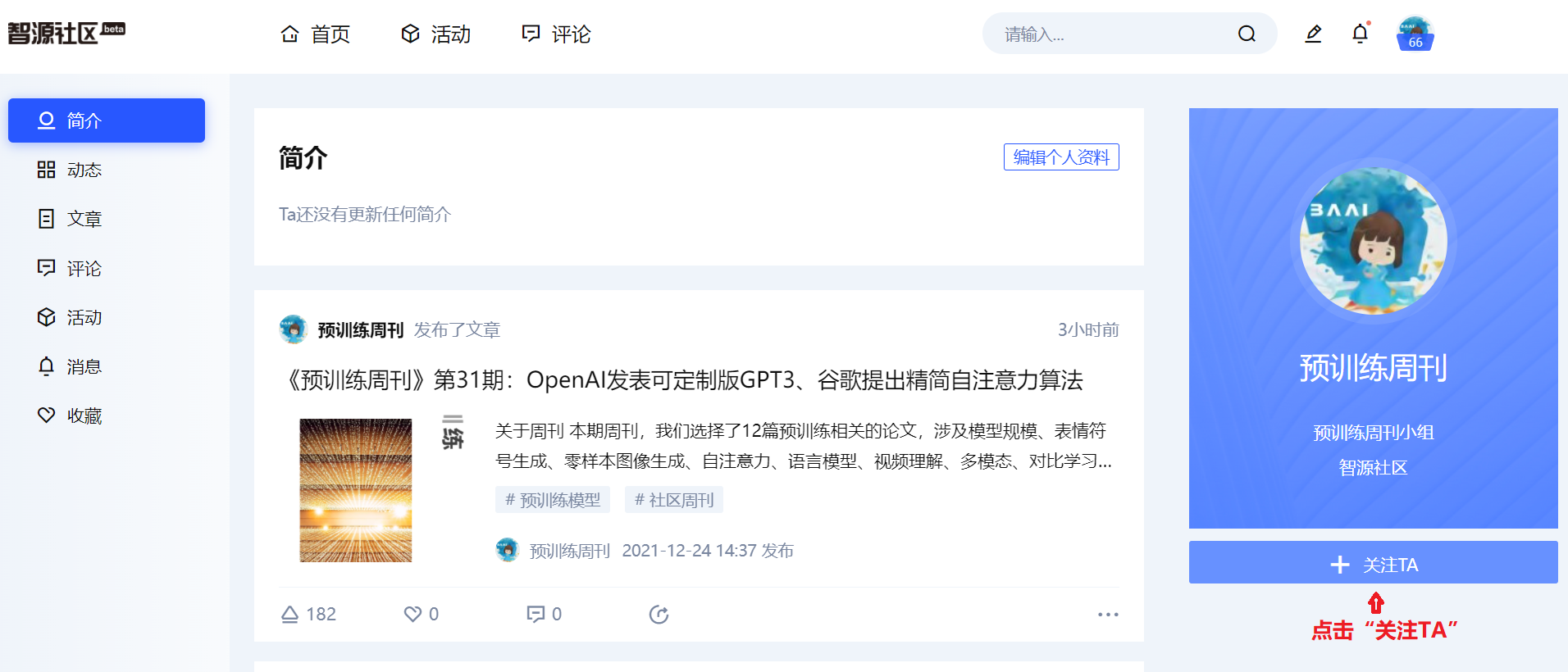
4,您已经完成《预训练周刊》订阅啦,以后智源社区自动向您推送最新版的《预训练周刊》!
论文推荐
【标题】谷歌、多伦多大学 | Exploring Length Generalization in Large Language Models(探索大型语言模型中的长度泛化)
作者:Cem Anil , Yuhuai Wu , Anders Andreassen ,等
简介:从短问题实例推断到较长问题实例的能力是推理任务中分布外泛化的一种重要形式,并且在从很少有较长问题实例的数据集中学习时至关重要。其中包括定理证明、解决定量数学问题以及阅读/总结小说。在本文中,作者进行了细致的实证研究,探索基于transformer的语言模型的长度泛化能力。作者首先确定:在长度泛化任务上简单地微调transformer、可以显示出与模型规模无关的显着泛化缺陷。然后作者展示了结合预训练的大型语言模型的上下文学习能力与暂存提示(要求模型在产生答案之前输出解决方案步骤)导致长度泛化的显着改进。作者对每种学习方式都进行了细致的失败分析,并确定了常见的错误来源,这些错误突出了使语言模型具备泛化到更长问题的能力的机会。
论文下载:https://arxiv.org/pdf/2207.04901.pdf
阅读详情
【标题】蚂蚁集团 | Learning Large-scale Universal User Representation with Sparse Mixture of Experts(使用专家的稀疏混合学习大规模通用用户表示)
作者:Caigao Jiang, Siqiao Xue, James Zhang,等
简介:本文研究通用的用户表示、被ICML 2022 Pre-training Workshop收录。由于随着时间推移的复杂的特征交互、以及用户特征的高维度,学习用户序列行为嵌入是非常复杂和具有挑战性的。最近出现的基础模型(例如BERT及其变体),鼓励大量研究人员在该领域进行研究。然而,与自然语言处理(NLP)任务不同,用户行为模型的参数主要来自用户嵌入层,这使得大多数现有工作无法训练大规模的通用用户嵌入。此外,用户表示是从多个下游任务中学习的,过去的研究工作没有解决跷跷板现象。在本文中,作者提出了 SUPERMOE,这是一个从多个任务中获得高质量用户表示的通用框架。具体来说,用户行为序列由 MoE Transformer 编码,因此可以将模型容量增加到数十亿参数、甚至数万亿参数。作者的方法在最先进的模型上实现了最佳性能,结果证明了作者框架的有效性。
论文下载:https://arxiv.org/pdf/2207.04648.pdf
阅读详情
【标题】荷兰蒂尔堡大学、联邦大学 | Neural Data-to-Text Generation Based on Small Datasets: Comparing the Added Value of Two Semi-Supervised Learning Approaches on Top of a Large Language Model(基于小数据集的神经数据到文本生成:在大型语言模型上比较两种半监督学习方法的附加值)
作者:Chris van der Lee, Thiago Castro Ferreira, Chris Emmery,等
简介:本研究讨论了半监督学习与预训练语言模型相结合对数据到文本生成的影响。本研究旨在通过将仅辅以语言模型的数据到文本系统与另外通过数据增强或伪标记半监督学习方法丰富的两个数据到文本系统进行比较来回答问题:当文本生成补充大规模语言模型时,尚不知半监督学习是否仍然有用。结果表明:半监督学习在多样性指标上的得分更高。在输出质量方面,使用伪标记方法扩展具有语言模型的数据到文本系统的训练集确实提高了文本质量分数,但数据增强方法在没有训练集扩展的情况下产生了与系统相似的分数。实验结果表明:即使存在语言模型,半监督学习方法也可以提高输出质量和多样性。
论文下载:https://arxiv.org/pdf/2207.06839.pdf
阅读详情
【标题】美国蒙大拿州立大学、科罗拉多大学 |Towards Multimodal Vision-Language Models Generating Non-Generic Text(迈向生成非通用文本的多模态视觉语言模型)
作者:Wes Robbins, Zanyar Zohourianshahzadi, Jugal Kalita
简介:本文研究作为适应性方法的特殊符号方法从图像中提取的附加信息,以提升视觉语言模型的效果。视觉语言模型可以评估图像中的视觉上下文并生成描述性文本。虽然生成的文本可能准确且语法正确,但通常过于笼统。为了解决这个问题,最近的工作使用光学字符识别来用从图像中提取的文本来补充视觉信息。在这项工作中,作者认为视觉语言模型可以从可以从图像中提取的附加信息中受益,但当前模型并未使用这些信息。作者修改了以前的多模式框架以接受来自任意数量的辅助分类器的相关信息。特别是,作者将人名作为一组额外的标记,并创建一个新颖的图像标题数据集,以方便使用人名进行标题。通过使用该数据集微调预训练模型,作者展示了一个模型,该模型可以通过对有限数据进行训练,自然地将面部识别标记集成到生成的文本中。
论文下载:https://arxiv.org/pdf/2207.04174.pdf
阅读详情
【标题】Meta AI | Make-A-Scene: Scene-Based Text-to-Image Generation with Human Priors(Make-A-Scene:基于场景和人类先验的文本-图像生成)
作者:Oran Gafni, Yaniv Taigman等
简介:本文介绍了交互可控的多模态预训练应用。近日Meta官宣推出Make-A-Scene模型,这是一个“交互式”和“可控”图像生成系统,可基于文本描述和粗略草图等生成更加契合用户需求的精美图片。本文有以下创新点:启用一个简单的控制机制,以场景的形式补充文本;引入一些元素,通过对关键图像区域(比如人脸和显著物体),采用特定领域的知识,大大改善标记化过程;以及为Transformer进行无分类器情况下的指导。本文的模型实现了最先进的FID和人类评估结果,解锁了生成512×512像素分辨率的高保真图像的能力,大大提高了视觉质量。通过场景可控性,本模型引入了多个新的应用:场景编辑,带锚点场景的文本编辑,克服分布外的文本提示,以及故事插图的生成。作者的目标是在未来提供更广泛的访问渠道,让更多的人有机会控制自己的创作,并解锁全新的表达形式。
论文下载:https://arxiv.org/pdf/2203.13131.pdf
阅读详情
【标题】UC伯克利、谷歌等 | LM-Nav: Robotic Navigation with Large Pre-Trained
Models of Language, Vision, and Action(LM-Nav:基于语言、视觉和行为大模型的机器人导航方法)
作者:Dhruv Shah, Sergey Levine等
简介:本文介绍了预训练模型在机器人上的应用。在机器人研究中,大型、未注释的数据集可以提供对现实世界的良好泛化,另外语言提供了更多便捷的与机器人交流方式,但现代方法通常需要带有注释轨迹的昂贵的监督式语言描述。本文提出了一个系统LM-Nav用于机器人导航,它可以在未注释的大型轨迹数据集上进行训练,同时仍然为用户提供高级界面。作者表明这样的系统可以完全由预训练的导航模型 (ViNG)、图像语言关联 (CLIP) 和语言建模 (GPT-3) 构建,无需任何微调或语言注释的机器人数据。本文展示了在真实世界的移动设备上实例化的LM-Nav机器人,并根据自然语言指令在复杂的户外环境中演示远视距导航。
论文下载:https://arxiv.org/pdf/2207.04429.pdf
阅读详情
【标题】浙大、联汇研究院 | VL-CheckList: Evaluating Pre-trained Vision-Language Models with Objects, Attributes and Relations(VL-CheckList:用对象、属性和关系评估预训练视觉语言模型)
作者:Tiancheng Zhao, Jianwei Yin等
简介:本文讨论了视觉语言预训练的评估标准。最近,由于多模态 Transformer 的出现和大型匹配图像文本语料库的可用性,VLP 取得了快速进展。当前评估 VLP 模型的实际方法是通过比较其微调的下游任务性能;这有许多局限性,比如可解释性差、结果不可比较、数据偏置等。本文提出了 VL-CheckList 方法,这是一个可解释的框架,全面评估 VLP 模型。VLCheckList 的核心原则主要有三点:评估VLP模型的基本能力,而不是下游应用的性能;将能力分解为更易于分析的相对独立的变量;语言感知的负样本采样策略,以创建难例负样本。在本文中,作者通过分析 7 种流行的 VLP 模型验证了所提出的方法,包括双编码器模型、基于区域的 VLP 模型和端到端 VLP 模型。
论文下载:https://arxiv.org/pdf/2207.00221.pdf
阅读详情
【标题】谷歌 | Does GNN Pretraining Help Molecular Representation?(图神经网络预训练帮助了分子表征吗)
作者:Ruoxi Sun
简介:本文讨论了图神经网络预训练在分子数据上是否有用。最近,图研究界一直试图复制自然语言处理中自监督预训练的成功,并声称取得了一些成功。然而,本文发现自监督预训练在分子数据上带来的好处在很多情况下是可以忽略不计的。本文对GNN预训练的关键部分进行了彻底的消融研究,包括预训练目标、数据分割方法、输入特征、预训练数据集规模和GNN架构,以决定下游任务的准确性。本文的第一个重要发现是,在许多情况下,自监督图预训练与非预训练方法相比没有统计学上的明显优势。第二,尽管通过额外的监督预训练可以观察到改善,但随着更丰富的特征或更平衡的数据分割,改善可能会减少。第三,与预训练任务的选择相比,实验性的超参数对下游任务的准确性有更大的影响。本文假设对分子的预训练的复杂性不够,导致下游任务的可迁移知识较少。
论文下载:https://arxiv.org/pdf/2207.06010v1.pdf
阅读详情
研究动态
【标题】BLOOM:BigScience开放训练的语言大模型完成了,1000人参与,1760亿参数,支持59种语言,现在就可以下载、使用
简介:凭借其 1760 亿个参数,BLOOM 能够生成 46 种自然语言和 13 种编程语言的文本。对于其中大部分语言模型(例如西班牙语、法语和阿拉伯语),BLOOM 将是第一个创建超过1000亿参数的语言模型。这是来自 70 多个国家和 250 多个机构的 1000 多名研究人员参与的一年工作的高潮,最终在法国巴黎南部的 Jean Zay 超级计算机上完成了 117 天(3 月 11 日至 7 月 6 日)BLOOM 模型的训练,感谢法国科研机构 CNRS 和 GENCI 提供的价值约 300 万欧元的计算资助。
阅读详情
【标题】语言AI原来知道自己的回答是否正确!伯克利等高校新研究火了
简介:语言AI,具备了人类的自我审视能力。最近,一个来自加州大学伯克利分校和霍普金斯大学的学术团队研究表明:大模型不仅能判断自己的答案正确与否,而且经过训练,还能预测自己知道一个问题答案的概率。这体现在语言AI回答问题时,会校准自己的答案,这里的校准,就是语言AI预测一个答案的正确概率,是否与实际发生的概率一致。本文得到了以下结论,在特定格式的选择题中,语言AI模型可以对答案进行很好的校准;如果在一个范围内,给AI模型提出若干问题,然后AI模型对这些问题的答案进行真假评价,具有合理的,且经过校准的置信度。这也证明,语言AI模型确实可以判断自己对一个问题的主张是否正确。对于这一学术成果,研究团队表示,将来的方向是将这些成果推广到语言AI模型在不模仿人类文本的前提下,完成自我学习和事实推理。
阅读详情
【标题】开源!港中文、MIT、复旦提出首个RNA基石模型
简介:不同于蛋白质领域,RNA 领域的研究往往缺少充足的标注数据,比如 3D 数据只有 1000 多个 RNA。这极大限制了机器学习方法在 RNA 结构功能预测任务中的开发。为了弥补标注数据的不足,本文展示了一项可为 RNA 各类研究提供丰富结构功能知识的基石模型 ——RNA foundation model (RNA-FM)。作为全球首个基于 23 million 的无标签 RNA 序列通过无监督方式训练得到的 RNA 基石模型,RNA-FM 挖掘出了 RNA 序列中蕴含的进化和结构模式。值得注意的是,RNA-FM 仅需要配比简单的下游模型,或是仅提供 embedding,就能够在很多下游任务中获得远超 SOTA 的表现,比如在二级结构预测中可以提升 20%,距离图预测可以提升 30%。大规模的实验证明,该模型具有极强的泛化性,甚至可以用于 COVID-19 以及 mRNA 的调控片段。RNA-FM 的出现一定程度上缓解了 RNA 带标注数据紧张的现状,其将以 RNA 领域基础模型的身份,为该领域的各种各样的研究提供强有力的支援与帮助。
阅读详情
欢迎加入预训练社群
如果你正在从事或关注预训练学习研究、实现与应用,欢迎加入“智源社区-预训练-交流群”。在这里,你可以:
-
学习前沿知识、求解疑难困惑
-
分享经验心得、展示风貌才华
-
参与专属活动、结识研究伙伴
请扫描下方二维码加入预训练群(备注:“姓名+单位+预训练”才会验证进群哦)

内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢