
关于周刊
本期周刊,我们选择了9篇预训练相关的论文,涉及提示调优、大模型指令、知识迁移、持续学习、机器翻译、多任务学习、蛋白质表征、蛋白质设计和蛋白质工程的探索。此外,在研究动态方面,我们选择了3篇预训练资讯,将介绍语言推理评估、检索模型和大模型哲学方面的一些最新内容。
周刊采用社区协作的模式产生,欢迎感兴趣的朋友们参与我们的工作,一起来推动预训练学习社群的分享、学习和交流活动。可以扫描文末的二维码加入预训练群。
(本期贡献者:申德周 翟珂 吴新刚)
关于周刊订阅
告诉大家一个好消息,《预训练周刊》开启“订阅功能”,以后我们会向您自动推送最新版的《预训练周刊》。订阅方法:
方式一:
扫描下面二维码,进入《预训练周刊》主页,选择“关注TA”。

方式二:
1,注册智源社区账号
2,点击周刊界面左上角的作者栏部分“预训练周刊”(如下图),进入“预训练周刊”主页。
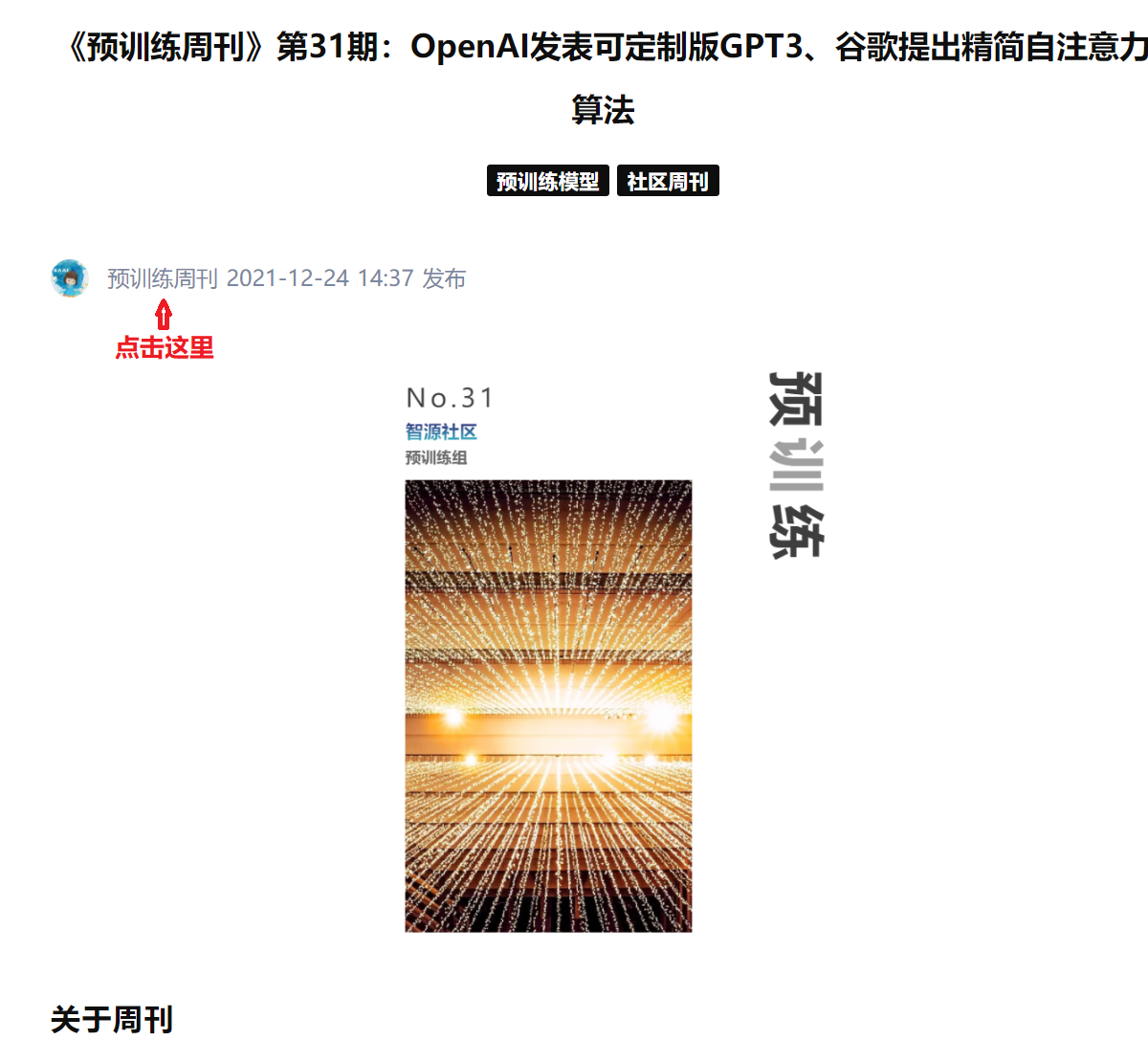
3,点击“关注TA”(如下图)
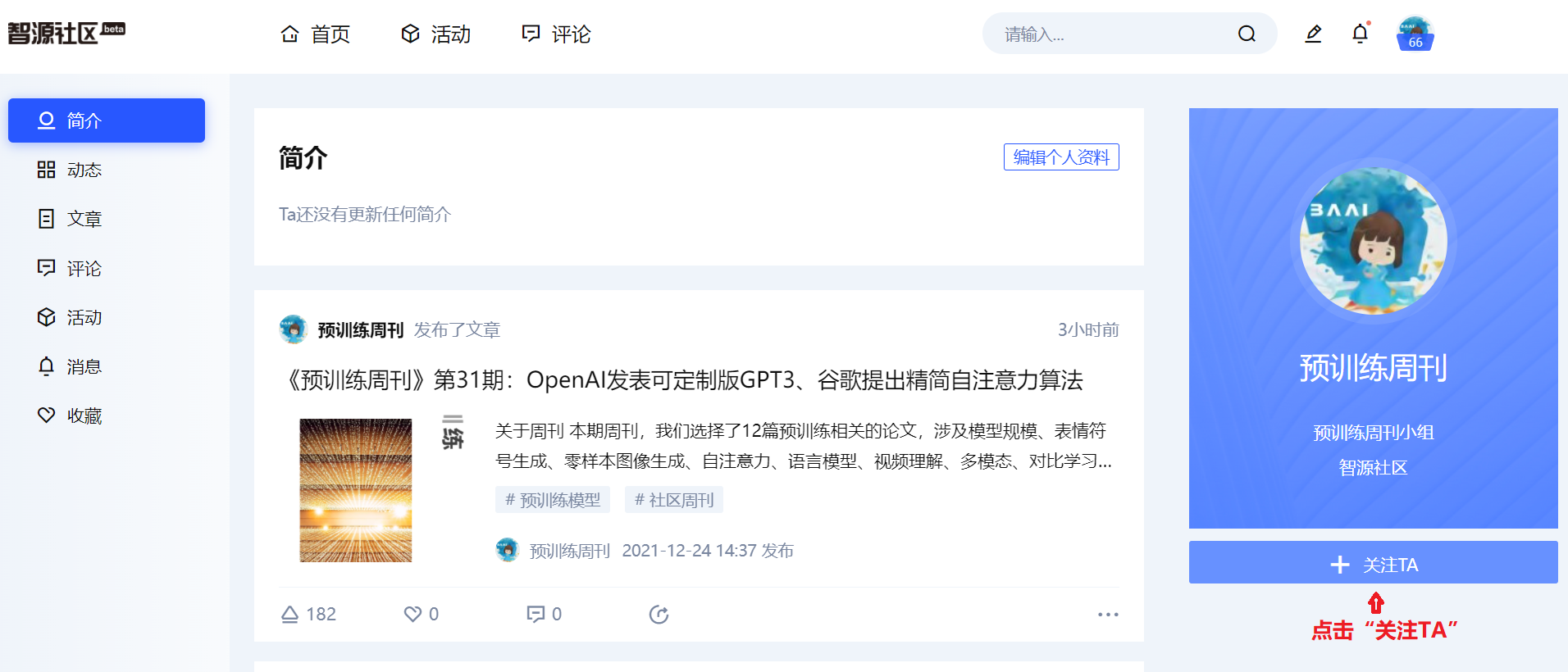
4,您已经完成《预训练周刊》订阅啦,以后智源社区自动向您推送最新版的《预训练周刊》!
论文推荐
标题:IBM、布朗大学、Huggingface、哈佛等|Interactive and Visual Prompt Engineering for Ad-hoc Task Adaptation with Large Language Models(具有大型语言模型的专有任务适应的交互式和视觉提示工程)
作者:Hendrik Strobelt, Albert Webson, Victor Sanh, Alexander M. Rush等
简介:本文介绍了一种大模型提示设计调优工具。为新任务找到 LLM 提示可能很困难。PromptIDE 允许用户尝试提示变量、可视化提示性能并迭代优化提示。
论文下载:https://arxiv.org/pdf/2208.07852
试用地址:https://prompt.vizhub.ai/
阅读详情
标题:谷歌|Do As I Can, Not As I Say: Grounding Language in Robotic Affordances(尽我所能,而不是我说的:将语言转化为机器人能力)
作者:Michael Ahn, Anthony Brohan, Noah Brown, Andy Zeng等
简介:本文介绍了一种语言模型转化为机器指令的方法。作者提出了一种与日常机器人合作开发的新颖方法,该方法利用高级语言模型知识使物理代理人(例如机器人)能够遵循以物理为基础的任务的高级文本指令,同时在任务中建立语言模型 在特定的现实世界环境中是可行的。作者通过将机器人放置在真实的厨房环境中并赋予它们以自然语言表达的任务来评估作者称之为 PaLM-SayCan 的方法。作者观察到时间扩展的复杂和抽象任务的高度可解释的结果,例如“我刚刚锻炼,请给我带点零食和饮料来恢复”。具体来说,作者证明在现实世界中将语言模型接地几乎可以将非真实基线的错误减少一半。作者也很高兴发布一个机器人模拟设置,研究社区可以在其中测试这种方法。
代码下载:https://github.com/google-research/google-research/tree/master/saycan
论文下载:https://arxiv.org/pdf/2204.01691
演示地址:https://sites.research.google/palm-saycan
阅读详情
标题:谷歌、DeepMind | Teacher Guided Training: An Efficient Framework for Knowledge Transfer(教师指导训练:知识转移的有效框架)
作者:Manzil Zaheer , Ankit Singh Rawat , Seungyeon Kim ,等
简介:大型预训练模型(例如 GPT-3)实现的显著性能提升,取决于它们在训练期间使用了大量的数据。类似地,将如此大的模型提炼成紧凑模型以进行有效部署也需要大量(标记或未标记)训练数据。在本文中,作者提出了教师指导训练框架 (TGT) ---用于训练一个高质量的紧凑模型,该模型利用预训练生成模型获得的知识,同时避免了处理大量数据的需要。TGT 利用了这样一个事实,即教师已经获得了基础数据域的良好表示,这通常对应于比输入空间低得多的维度流形。此外,作者可以使用教师模型通过采样或基于梯度的方法更有效地探索输入空间;因此,使 TGT 对于有限数据或长尾设置特别有吸引力。作者在泛化范围内正式捕获了提议的数据域探索的这种好处。作者发现 TGT 可以提高多个图像分类基准以及一系列文本分类和检索任务的准确性。
论文下载:https://arxiv.org/pdf/2208.06825.pdf
阅读详情
标题:滑铁卢大学 |Continuous Active Learning Using Pretrained Transformers(使用预训练的 Transformer 进行持续主动学习)
作者:Nima Sadri, Gordon V. Cormack
简介:本文研究基于Transformer的模型的持续主动学习。BERT 和 T5 等预训练和微调的 Transformer 模型提高了即席检索和问答的最新技术水平,但在高召回率信息检索方面还没有提高,其目标是检索基本上所有相关的文件。作者研究使用基于Transformer的模型进行重新排序和/或特征化是否可以改进 TREC 总召回跟踪的基线模型实现,这代表了高召回信息检索的当前技术水平。作者还介绍了 CALBERT,该模型可用于根据相关反馈不断微调基于 BERT 的模型。
论文下载:https://arxiv.org/pdf/2208.06955.pdf
阅读详情
标题:爱尔兰都柏林城市大学、爱尔兰国立学院、都柏林科技大学 | Domain-Specific Text Generation for Machine Translation(机器翻译的领域特定文本生成)
作者:Yasmin Moslem , Rejwanul Haque , John D. Kelleher ,等
简介:本文研究以预训练语言模型为机器翻译进行特定领域的数据扩充。保存从源到目标的领域知识在任何翻译工作流程中都至关重要。在翻译行业中,接收高度专业化的项目很常见,其中几乎没有任何并行的域内数据。在没有足够的域内数据来微调机器翻译 (MT) 模型的情况下,生成与相关上下文一致的翻译具有挑战性。在这项工作中,作者提出了一种新的域适应方法:利用最先进的预训练语言模型 (LM) 用于 MT 的特定域数据增强,模拟 (a) 小型双语数据集或(b) 待翻译的单语源文本。将这个想法与反向翻译相结合,作者可以为这两个用例生成大量合成的双语域内数据。具体地说:针对上述两种情况,作者提出的方法在阿拉伯语到英语、和英语到阿拉伯语的语言对上分别实现了大约 5-6 BLEU 和 2-3 BLEU 的改进。
论文下载:https://arxiv.org/ftp/arxiv/papers/2208/2208.05909.pdf
阅读详情
标题:印度理工学院 | Multi-task Active Learning for Pre-trained Transformer-based Models(预训练Transformer模型的多任务主动学习)
作者:Guy Rotman, Roi Reichart
简介:本文介绍了用预训练进行多任务主动学习。主动学习的一个最核心问题就是每次从未标注的样本中选出最困难的样本。一般的方法往往包括随机、熵、Dropout Agreement等的方式来决定并最终进行聚合量化困难程度。本文提出了3种新的多任务指标MT-PAR、MT-RRF和MT-IND。MT-PAR即把每一个样本的不确定量化值看成一个向量,如果一个样本对应向量中存在一个元素小于其他所有样本的向量对应位置的元素或者一个样本所有元素都小于其他样本向量对应位置元素的时候,该样本就是被选择的困难样本;MT-RRF对于每一个样本首先计算得到其t个任务对应的ST-EC值并进行倒数求和,最大值为困难样本;MT-IND假设要选n个样本,一个t个任务,那么就每个任务根据ST-EC值选出n/t个样本。总体上本文介绍了多任务数据和多任务模型,探讨了在同一份数据集上做不同的任务所导致了标注数据昂贵进而采用了主动学习的问题。
论文下载:https://arxiv.org/pdf/2208.05379.pdf
阅读详情
标题:Deeplab | DENVIS: scalable and high-throughput virtual screening using graph neural networks with atomic and surface protein pocket features(DENVIS:利用图神经网络的原子和表面蛋白质口袋特征进行可扩展和高通量的虚拟筛选)
作者:Agamemnon Krasoulis, Nick Antonopoulos, Vassilis Pitsikalis, Stavros Theodorakis
简介:本文展示了一个预训练在药物虚拟筛选上的应用。虚拟筛选的计算方法可以通过识别特定靶点的潜在hits而大大加速早期药物发现,传统的对接算法使用基于物理学的模拟来计算输入的蛋白质-配体对的结合方向和结合亲和力分数。本文介绍了深度神经虚拟筛选DENVIS,这是一个使用预训练的图神经网络进行虚拟筛选的端到端流程。通过在两个基准数据库上的实验,本文的方法与一些基于对接、基于机器学习和基于对接/机器学习的混合算法相比,表现得很有竞争力。本文的方法的一些关键要素包括使用原子和表面特征的组合进行蛋白质口袋建模,使用模型集成,图神经网络预训练以及负采样进行数据增强。总之,DENVIS达到了与最先进的虚拟筛选技术相媲美的性能,可以利用最少的计算资源将虚筛扩展到数十亿分子。
论文下载:https://doi.org/10.1101/2022.03.17.484710
阅读详情
标题:蒙彼利埃大学、BionomeeX |PeTriBERT : Augmenting BERT with tridimensional encoding for inverse protein folding and design(PeTriBERT:用于蛋白质逆折叠和设计的三维编码增强BERT)
作者:Baldwin Dumortier, Antoine Liutkus, Clément Carré, Gabriel Krouk
简介:本文展示了一种融合结构信息的预训练方法。自从最近新的折叠方法取得突破以来,可用的结构数据量不断增加,这缩小了基于数据驱动的序列方法和结构方法之间的差距。本文专注于逆折叠问题,从蛋白质三维结构中预测条氨基酸序列。为此,作者从自然语言处理增强的三维结构数据中引入了一个简单的Transformer模型,并把由此产生的模型称为PeTriBERT:在BERT模型中嵌入三维表征的蛋白质。本文在从新获得的AlphaFoldDB数据库中检索到的350,000多条蛋白质序列上训练这个小型的4000万参数模型。使用PetriBert,能够在与吉布斯采样结合的虚拟计算中生成具有类似GFP结构的全新蛋白质,这表明PetriBert确实捕捉到了蛋白质的折叠规则,并可能成为蛋白质设计的一个重要工具。
论文下载:https://doi.org/10.1101/2022.08.10.503344
阅读详情
标题:中科院 | Protein engineering via Bayesian optimization-guided evolutionary algorithm and robotic experiments(通过贝叶斯优化指导的进化算法和机器人实验的蛋白质工程)
作者:Yu Qiao, Tong Si 等
简介:本文展示了一个预训练与贝叶斯优化在蛋白自动化设计上的应用。蛋白质工程的目的是在一个巨大的设计空间中找到更好的功能序列。本文展示了一种可扩展的、分批进行的方法,即贝叶斯优化引导的进化(BO-EVO)算法,在预训练模型的蛋白质适应度景观基础上探索组合突变库,并指导多轮机器人实验。本文首先研究了基于蛋白质GB1基准的景观的各种设计,然后将BO-EVO成功地推广到另一个大肠杆菌激酶PhoQ上。这种方法随后被应用于指导机器人库的创建和筛选,以设计RhlA的酶特异性,RhlA是鼠李糖脂生物表面活性剂的一种关键生物合成酶。经过4次迭代,本算法在检查了所有可能的突变体中不到1%的突变体后,在生产目标鼠李糖脂同系物方面取得了4.8倍的改进。总的来说,BO-EVO被证明是一种高效和通用的方法,可以在没有先验知识的情况下指导蛋白工程。
论文下载:https://doi.org/10.1101/2022.08.11.503535
阅读详情
研究动态
标题:德国比勒费尔德大学 | MENLI: Robust Evaluation Metrics from Natural Language Inference(基于自然语言推理的稳健评估指标)
作者:Yanran Chen, Steffen Eger
简介:最近提出的基于BERT的评估指标在标准评估基准上表现良好,但容易受到对抗性攻击,例如与真实性错误相关的攻击。作者认为这(部分)源于这样一个事实,即它们是语义相似性的模型。相反,作者开发了基于自然语言推理(NLI)的评估指标,作者认为这是一种更合适的建模方法。作者设计了一个基于偏好的对抗攻击框架,并表明作者基于NLI的指标比最近基于BERT的指标对攻击更具鲁棒性。在标准基准上,作者基于NLI的指标优于现有的摘要指标,但性能低于SOTA MT指标。然而,当作者将现有指标与作者的NLI指标相结合时,作者既获得了更高的对抗鲁棒性(+20%至+30%),也获得了标准基准上更高质量的指标(+5%至+25%)。
论文下载:https://arxiv.org/pdf/2208.07316.pdf
阅读详情
标题:Meta发布全新检索增强语言模型Atlas,110亿参数反超5400亿的PaLM
作者:Gautier Izacard, Patrick Lewis, Maria Lomeli,等
简介:最近,Meta推出了一个全新的检索增强的语言模型——Atlas。和那些动辄上千亿参数的前辈们不同,Atlas只有110亿的参数。值得注意的是:Atlas虽然只有PaLM的1/50,但它只用了64个例子就在NaturalQuestions达到了42%以上的准确率,比PaLM这个5400亿参数的模型还高出了3%。实验结果表明:Atlas在few-shot问题回答(NaturalQuestions和TriviaQA)和事实核查(FEVER)上的表现优于更大的非增强模型,分别是超出了2.8%,3.3%和5.1%。并且,Atlas在各种真实世界的测试(MMLU)上能与具有15倍以上参数的模型相当或更强。此外,Atlas在全数据集设置中也刷新了SOTA。在NaturalQuestions上把准确率提高了8.1%,在TriviaQA上提高了9.3%,在5个KILT任务上也是如此。更重要的是,Atlas检索到的段落可以被直接查验,从而获得更好的可解释性。此外还可以通过编辑甚至完全替换Atlas用于检索的语料库的方式,来保持模型一直都是最新的,无需重新训练。
论文链接:https://arxiv.org/abs/2208.03299
阅读详情
标题:薛定谔的 AI 大模型:箱子暂不能打开,但钱还要继续「烧」
简介:近几年的 AI 发展中,却出现了这样一个貌似违背资本规律的「怪异」现象:不管是学术界还是工业界,不管是大公司还是小公司,不管是私企还是国家资助的研究院,都在花大价钱「炼」大模型。导致圈内有两种声音:一种声音说,大模型已在多种任务基准上展现出强大的性能与潜力,未来一定是人工智能的发展方向,此时的投入是为将来不错过时代大机遇做准备,投入成百上千万(或更多)训练是值得的。换言之,抢占大模型高地是主要矛盾,高成本投入是次要矛盾。另一种声音则说,在 AI 技术落地的实际过程中,当前对大模型的全面吹捧不仅抢夺了小模型与其他 AI 方向的研究资源,而且由于投入成本高,在解决实际的产业问题中性价比低,也无法在数字化转型的大背景中造福更多的中小企业。本文认为,这其中核心矛盾就是如何提升大模型的训练速度、降低训练的成本,或提出新的架构。
阅读详情
欢迎加入预训练社群
如果你正在从事或关注预训练学习研究、实现与应用,欢迎加入“智源社区-预训练-交流群”。在这里,你可以:
-
学习前沿知识、求解疑难困惑
-
分享经验心得、展示风貌才华
-
参与专属活动、结识研究伙伴
请扫描下方二维码加入预训练群(备注:“姓名+单位+预训练”才会验证进群哦)

内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢