
关于周刊
本期周刊,我们选择了9篇预训练相关的论文,涉及大模型推理、训练加速、文本表征、实体理解、代码检索、抗体优化、分子表征、基因致病性预测和突变预测的探索。此外,在研究动态方面,我们选择了6篇预训练资讯,将介绍情感识别、多模态、图像大模型训练、大模型研究范式、图像生成和多模态表示方面的一些最新内容。
周刊采用社区协作的模式产生,欢迎感兴趣的朋友们参与我们的工作,一起来推动预训练学习社群的分享、学习和交流活动。可以扫描文末的二维码加入预训练群。
(本期贡献者:申德周 翟珂 吴新刚)
关于周刊订阅
告诉大家一个好消息,《预训练周刊》开启“订阅功能”,以后我们会向您自动推送最新版的《预训练周刊》。订阅方法:
方式一:
扫描下面二维码,进入《预训练周刊》主页,选择“关注TA”。

方式二:
1,注册智源社区账号
2,点击周刊界面左上角的作者栏部分“预训练周刊”(如下图),进入“预训练周刊”主页。
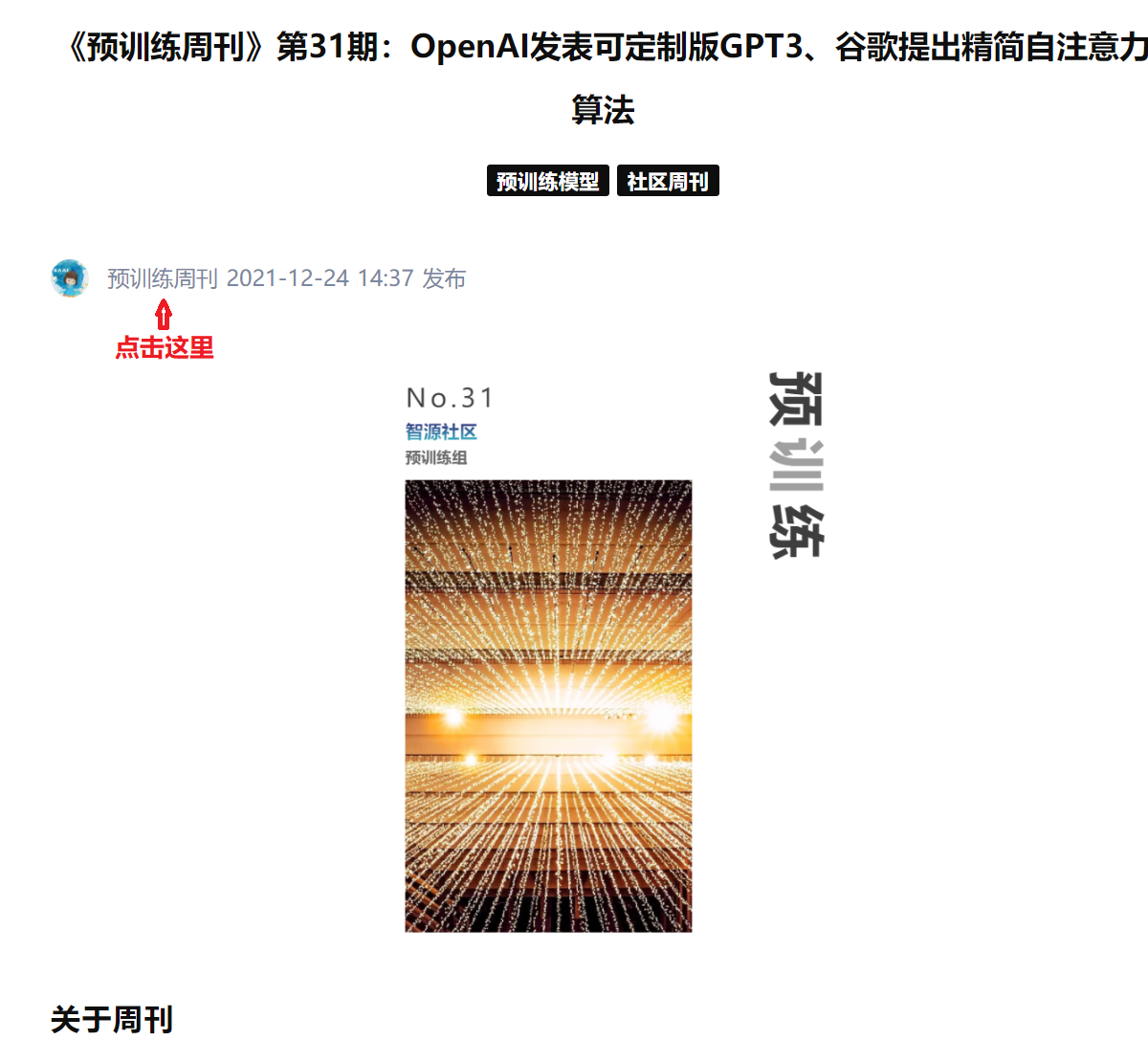
3,点击“关注TA”(如下图)
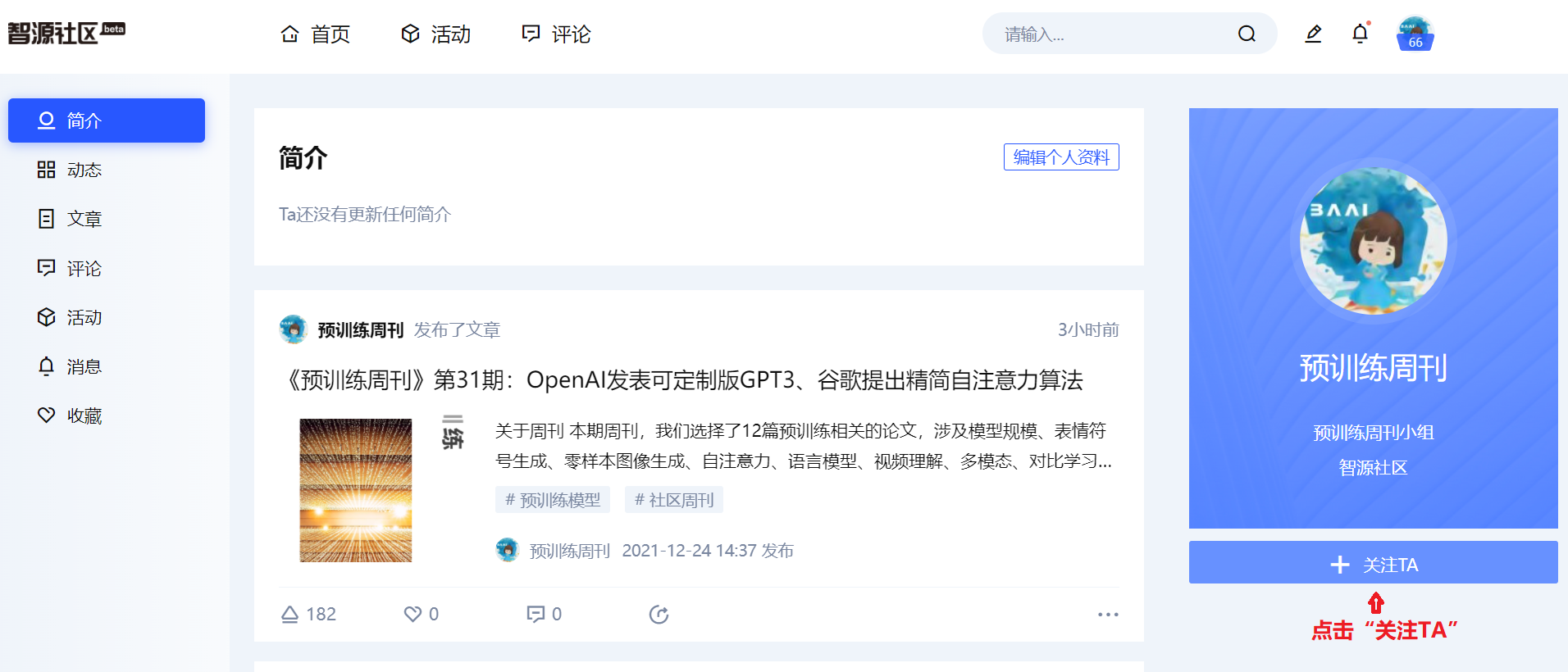
4,您已经完成《预训练周刊》订阅啦,以后智源社区自动向您推送最新版的《预训练周刊》!
论文推荐
标题:DeepMind|Faithful Reasoning Using Large Language Models(使用大型语言模型进行可信推理)
作者:Antonia Creswell, Murray Shanahan
简介:本文研究了大模型在推理领域的效果。尽管当代大型语言模型 (LM) 展示了令人印象深刻的问答能力,但它们的答案通常是对模型的一次调用的产物。这会带来不受欢迎的不透明程度并影响性能,尤其是在本质上是多步骤的问题上。为了解决这些限制,作者展示了如何通过一个因果结构反映问题的潜在逻辑结构的过程来使 LMs 执行忠实的多步推理。作者的方法通过将推理步骤链接在一起来工作,其中每个步骤都来自对两个微调LM的调用,一个用于选择,一个用于推理,以产生有效的推理跟踪。作者的方法通过推理轨迹空间进行波束搜索以提高推理质量。作者证明了作者的模型在多步逻辑推理和科学问答方面的有效性,表明它在最终答案准确性方面优于基线,并生成了人类可解释的推理轨迹,其有效性可以由用户检查。
论文下载:https://arxiv.org/pdf/2208.14271v1.pdf
阅读详情
标题:亚利桑那大学 | A Compact Pretraining Approach for Neural Language Models(神经语言模型的紧凑预训练方法)
作者:Shahriar Golchin, Mihai Surdeanu, Nazgol Tavabi, 等
简介:本文研究通过紧凑预训练方法以降本增效。大型神经语言模型(NLM)的领域自适应与预训练阶段的大量非结构化数据相结合。然而,在本研究中,作者表明:预训练的NLM从集中于域中关键信息的数据的紧凑子集中更有效、更快地学习域内信息。作者使用抽象摘要和提取关键字的组合从非结构化数据中构造这些紧凑子集。特别是,作者依赖BART生成抽象摘要,而KeyBERT从这些摘要(或直接从原始非结构化文本)中提取关键词。作者使用六种不同的设置来评估其方法,实验结果表明:在使用作者的方法进行预训练的NLMs之上训练的任务特定分类器优于基于传统预训练的方法,即对整个数据进行随机掩蔽、以及不进行预训练。此外,作者还表明与vanilla 预训练相比,作者的策略将预训练时间缩短了五倍。
论文下载:https://arxiv.org/pdf/2208.12367.pdf
代码下载:https://github.com/shahriargolchin/compact-pretraining
阅读详情
标题:Primer科技公司 | Neural Embeddings for Text(文本的神经嵌入)
作者:Oleg Vasilyev, John Bohannon
简介:本文研究表达文本向量的新方法:神经嵌入。作者提出了一种自然语言文本嵌入的新方法,用于:深刻地表达语义。不同于:标准文本嵌入使用预训练语言模型的向量输出,在作者的方法中:作者让语言模型从文本中学习,然后从字面上选择它的大脑、取模型神经元的实际权重来生成向量。作者将文本的这种表示称为神经嵌入。据作者所知:这是首次尝试以这种方式获得表示;原则上,该技术不限于文本。该技术可以推广到文本和语言模型之外,但作者首先探讨其在自然语言处理中的特性。作者在多个数据集上比较了神经嵌入和GPT语句(SGPT)嵌入。作者观察到:神经嵌入在小得多的模型中实现了相当的性能,并且不同数据集时误差是不同的。
论文下载:https://arxiv.org/pdf/2208.08386.pdf
阅读详情
标题:芝加哥丰田技术研究所 | Efficient and Interpretable Neural Models for Entity Tracking(用于实体跟踪的高效且可解释的神经模型)
作者:Shubham Toshniwal
简介:本文研究在长文档与语言模型中集成实体跟踪。自然语言模型需要什么才能理解类似指环王的小说?这种模型至少必须能够:(1)识别和记录文本中引入的新字符(实体)及其属性,以及(2)识别先前引入的字符的后续引用并更新其属性。实体跟踪问题对于语言理解至关重要,因此对于自然语言处理中的广泛下游应用非常有用。在这篇论文中,作者提出计算效率高的实体跟踪模型,可以通过使用从预训练语言模型导出的丰富的固定维向量表示来表示实体,并利用实体的短暂性质来开发。作者还主张将实体跟踪集成到语言模型中,因为这将允许:(1)考虑到当前在NLP应用中普遍使用预训练语言模型,更广泛的应用,以及(2)更容易采用,因为在新的预训练语言模型中交换比集成单独的独立实体跟踪模型容易得多。
论文下载:https://arxiv.org/pdf/2208.14252.pdf
阅读详情
标题:人大、中山大学、微软、纽卡斯尔大学 | Long Code for Code Search(用于代码搜索的长代码)
作者:Fan Hu, Yanlin Wang, Lun Du,等
简介:本文研究当前预训练模型无法解决长代码的议题。由于基于transformer的预训练模型,代码搜索的性能得到了显著提高。然而,由于多头自注意力和GPU内存的限制,输入符号长度有限制,现有的如CodeBERT等预训练代码模型:默认采用前256个符号,这使得它们无法表示大于256个符号的长代码的完整信息。将长文本处理方法直接应用于长代码是不合理的,因为:与可被视为具有完整语义的整体的长文本文档不同,长代码的语义是不连续的:因为一段长代码可能包含不同的代码模块。为解决长代码问题,作者提出了MLCS:为代码搜索建模长代码,以获得长代码的更好表示。MLC使用基于transformer的预训练模型来建模长代码,而不改变其内部结构和重新预训练。实验结果表明MLC对长代码检索有效:基于AST的分割和基于注意力的融合方法,MLCS实现了0.785的MRR分数,优于公共CodeSearchNet基准上的SOTA结果。
论文下载:https://arxiv.org/pdf/2208.11271.pdf
阅读详情
标题:Absci | Antibody optimization enabled by artificial intelligence predictions of binding affinity and naturalness(通过对结合亲和力和自然性的人工智能抗体优化)
作者:Sharrol Bachas, Roberto Spreafico等
简介:本文介绍了预训练语言模型在抗体序列优化上的应用。本文证明了根据高通量亲和力数据训练的预训练语言模型可以定量预测未见过的抗体序列变体的结合。经过验证,该模型可以高精度地定量预测未知抗体变体的结合亲和力,实现虚拟筛选,并将可访问序列空间扩大了几个数量级。在实验室中的预测和后续设计可以确认成功率远远高于传统筛选。本文的模型揭示了强烈的表观效应,这突出了对智能筛选方法的需求。此外,本文还介绍了自然性的概念,这是一个对抗体变体与天然免疫球蛋白的相似度进行评分的指标。本文表明,自然度与药物可开发性和免疫原性的衡量标准有关,而且它可以与结合亲和力一起使用遗传算法进行优化。这种方法有望加速和改善抗体工程,并可能提高开发新型抗体和相关候选药物的成功率。
论文下载:https://doi.org/10.1101/2022.08.16.504181
阅读详情
标题:中科大、微软 | Unified 2D and 3D Pre-Training of Molecular Representations(统一的2D和3D分子表征预训练)
作者: Jinhua Zhu, Tie-Yan Liu等
简介:本文介绍了分子多模态预训练。化学空间中分子2D表示与3D表示是互补的,即2D图关注原子的拓扑连接,3D构象关注原子的空间排列,但只有有限的工作将它们结合在一起。以往的方法的训练目标是最大化分子的2D和3D视图之间的互信息,其中2D视图和3D视图使用两个不同的模块进行编码。本文提出了一种在一个模型中同时处理分子的2D和3D信息的统一方法。作者设计了多个预训练任务:(1)掩蔽原子和坐标的重建,即在非掩蔽原子的基础上重建随机掩蔽的原子和坐标;(2)以2D图为条件的3D构象生成,即基于分子的2D图形生成3D构象;(3)以3D构象为条件的2D图形生成,即基于分子的3D构象生成2D图形。本文在11项下游分子性质预测实验中取得了10个最先进结果,与纯2D任务相比,平均提高了8.3%。在两个三维构象生成任务上也取得了显著的改进。
论文下载:https://dl.acm.org/doi/10.1145/3534678.3539368
阅读详情
标题:哥伦比亚大学 | SHINE: Protein Language Model based Pathogenicity Prediction for Inframe Insertion and Deletion Variants(SHINE: 基于蛋白质语言模型的框内插入删除突变的致病性预测)
作者: Xiao Fan, Yufeng Shen等
简介:本文介绍了蛋白预训练在致病性预测上的应用。框内插入和缺失突变改变了蛋白质的序列和长度并可能导致疾病,准确的致病性预测在人类疾病的遗传学研究中非常重要。现有的方法主要使用人工编码的特征,包括保守度、蛋白质结构和功能以及等位基因频率。本文开发了一个新的致病性预测器:SHINE,其使用预训练蛋白质语言模型,从蛋白质序列和多重序列比对中构建出一个隐藏表征,并将隐藏表征送入有监督的机器学习模型进行致病性预测。在两个测试数据集ClinVar和gnomAD中,SHINE对删除和插入的突变都取得了比现有方法更好的预测性能。本文的工作表明:无监督的蛋白质语言模型可以提供有价值的蛋白质信息,基于这些模型的新方法可以改善遗传分析中的突变预测和解释。
论文下载:https://dl.acm.org/doi/10.1145/3534678.3539368
阅读详情
标题:加州伯克利 | DNA language models are powerful zero-shot predictors of non-coding variant effects(DNA语言模型是强大的非编码突变效应的零样本预测器)
作者:Gonzalo Benegas, Sanjit Singh Batra, Yun S. Song
简介:本文介绍了DNA预训练的零样本预测能力。基因组预训练网络GPN可以仅使用基因组DNA序列的无监督预训练来学习非编码DNA的突变效应,还能够在没有任何监督的情况下学习到基因结构和DNA基序。本文通过展示其在拟南芥中达到最先进的性能来证明其效用(拟南芥是植物生物学的模型生物)。尽管只在DNA序列上进行了训练,GPN的性能超过了在拟南芥功能基因组学数据上训练的DeepSEA模型。此外,仅在单一基因组上训练的GPN优于广泛使用的保守度分数(如phyloP和PhastCons),这些评分分数于18个相关物种的全基因组比对。GPN对DNA序列的内部表示能够准确区分基因组区域(如内含子、非翻译区和编码序列)。GPN预测的置信度也可用于阐明调控语法(如转录因子结合基序)。本文的研究结果为建立最先进的非编码突变效应预测铺平了道路,即使在没有昂贵的功能基因组学数据的情况下,仅使用其基因组序列就可以为任何给定的物种提供预测。
论文下载:https://doi.org/10.1101/2022.08.22.504706
阅读详情
研究动态
标题:四川大学、澳大利亚阿德莱德大学、中国电子科大联合 | Pretrained Language Encoders are Natural Tagging Frameworks for Aspect Sentiment Triplet Extraction(预训练语言编码器是用于属性情感三元组提取的自然标记框架)
作者:Yanjie Gou, Yinjie Lei, Lingqiao Liu,等
简介:本文研究将预训练语言编码器作为三元组提取的自然标记框架。属性情感三元组提取(ASTE)旨在将方面、观点及其情感关系的跨度提取为情感三元组。现有的工作通常将跨度检测描述为一维标记问题,并使用二维标记矩阵对情感识别进行建模。此外,通过利用BERT等预训练语言编码器(PLE)的符号表示,它们可以实现更好的性能。然而,它们只是利用PLE作为特征提取器来构建模块,但从未深入了解PLE包含哪些特定知识。在本文中,作者认为与进一步设计模块来捕捉ASTE的归纳偏差不同,PLE本身包含“足够”的1D和2D标记特征:(1)标记表示包含标记本身的上下文意义,因此该级别特征包含1D标记所需的信息。(2) 不同PLE层的注意矩阵可以进一步捕获存在于标记对中的多级语言知识,这有利于二维标注。(3) 此外通过简单的转换,这两个特征也可以分别轻松地转换为2D标记矩阵和1D标记序列。广泛的实验证明:PLE可以成为自然的标签框架、并达到新的SOTA水平。
论文下载:https://arxiv.org/pdf/2208.09617.pdf
阅读详情
标题:通用多模态基础模型BEiT-3:引领文本、图像、多模态预训练迈向“大一统”
简介:微软亚洲研究院联合微软图灵团队推出了最新升级的 BEiT-3 预训练模型,在广泛的视觉及视觉-语言任务上,包括目标检测(COCO)、实例分割(COCO)、语义分割(ADE20K)、图像分类(ImageNet)、视觉推理(NLVR2)、视觉问答(VQAv2)、图片描述生成(COCO)和跨模态检索(Flickr30K,COCO)等,实现了 SOTA 的迁移性能。BEiT-3 创新的设计和出色的表现为多模态研究打开了新思路,也预示着 AI 大一统渐露曙光。
阅读详情
标题:FlagAI新增视觉模型!支持一键训练Swin Transformer
简介:FlagAI飞智是一个快速、易于使用和可扩展的AI基础模型工具包。 支持一键调用多种主流基础模型,同时适配了中英文多种下游任务。FlagAI支持最高百亿参数的悟道GLM(详见GLM介绍),同时也支持BERT、RoBERTa、GPT2、T5 模型、Meta OPT模型、ViT系列模型和 Huggingface Transformers 的模型。FlagAI提供 API 以快速下载并在给定(中/英文)文本上使用这些预训练模型,你可以在自己的数据集上对其进行微调(fine-tuning)或者应用提示学习(prompt-tuning)。FlagAI提供丰富的基础模型下游任务支持,例如文本分类、信息提取、问答、摘要、文本生成、图文匹配、图像分类等,对中英文都有很好的支持。FlagAI由三个最流行的数据/模型并行库(PyTorch/Deepspeed/Megatron-LM)提供支持,它们之间实现了无缝集成。 在FlagAI上,你可以用不到十行代码来并行你的训练、测试过程,也可以方便的使用各种模型提速技巧。
代码下载:https://github.com/BAAI-Open/FlagAI
阅读详情
标题:大模型铺天盖地出现后,计算机科学终成「自然科学」
简介:大型学习模型的出现从根本上改变了人工智能研究的性质。最近研究人员在使用 DALL-E 时,认为它似乎已经发展出自己的特有语言,如果人类能掌握它,或许可以更好地与 DALL-E 交互。也有研究人员发现,可以通过在 prompt 中添加某些神奇的咒语(比如「让我们一步步地思考」)来改善 GPT3 对推理问题的表现。现在 GPT3 和 DALL-E 这样的大型学习模型就像是「外星物种」一样,我们要尝试解码它们的行为。
阅读详情
标题:StabilityAI宣布公开Stable Diffusion模型
简介:StabilityAI CEO Emad Mostaque 在官博上宣布Stable Diffusion 开源。该模型是按照 Creative ML OpenRAIL-M 许可证 发布的。这是一个允许商业和非商业用途的许可许可证。
阅读详情
标题:覆盖200+服务场景,阿里「通义」大模型系列打造国内首个AI统一底座
简介:9 月 2 日,在阿里达摩院主办的世界人工智能大会「大规模预训练模型」主题论坛上,阿里巴巴资深副总裁、达摩院副院长周靖人发布阿里巴巴最新「通义」大模型系列,其打造了国内首个 AI 统一底座,并构建了通用与专业模型协同的层次化人工智能体系,将为 AI 从感知智能迈向知识驱动的认知智能提供先进基础设施,在业界首次实现模态表示、任务表示、模型结构的统一。通过这种统一学习范式,通义统一底座中的单一 M6-OFA 模型,在不引入任何新增结构的情况下,可同时处理图像描述、视觉定位、文生图、视觉蕴含、文档摘要等 10 余项单模态和跨模态任务,并达到国际领先水平。近期 M6-OFA 完成升级后可处理超过 30 种跨模态任务。通义统一底座中的另一组成部分是模块化设计,它借鉴了人脑模块化设计,以场景为导向灵活拆拔功能模块,实现高效率和高性能。
阅读详情
欢迎加入预训练社群
如果你正在从事或关注预训练学习研究、实现与应用,欢迎加入“智源社区-预训练-交流群”。在这里,你可以:
-
学习前沿知识、求解疑难困惑
-
分享经验心得、展示风貌才华
-
参与专属活动、结识研究伙伴
请扫描下方二维码加入预训练群(备注:“姓名+单位+预训练”才会验证进群哦)

内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢