
关于周刊
本期周刊,我们选择了8篇预训练相关的论文,涉及理解和生成统一对话模型、预训练噪音、多语言学习公平性、预训练演绎推理、视觉prompt生成、通用基础Transformer、地图定位、抗体库优化上的探索。此外,在研究动态方面,我们选择了2篇预训练资讯,将介绍微信大语言模型WeLM和大一统模型的理解的一些最新内容。
周刊采用社区协作的模式产生,欢迎感兴趣的朋友们参与我们的工作,一起来推动预训练学习社群的分享、学习和交流活动。可以扫描文末的二维码加入预训练群。
(本期贡献者:申德周 翟珂 吴新刚)
关于周刊订阅
告诉大家一个好消息,《预训练周刊》开启“订阅功能”,以后我们会向您自动推送最新版的《预训练周刊》。订阅方法:
方式一:
扫描下面二维码,进入《预训练周刊》主页,选择“关注TA”。

方式二:
1,注册智源社区账号
2,点击周刊界面左上角的作者栏部分“预训练周刊”(如下图),进入“预训练周刊”主页。
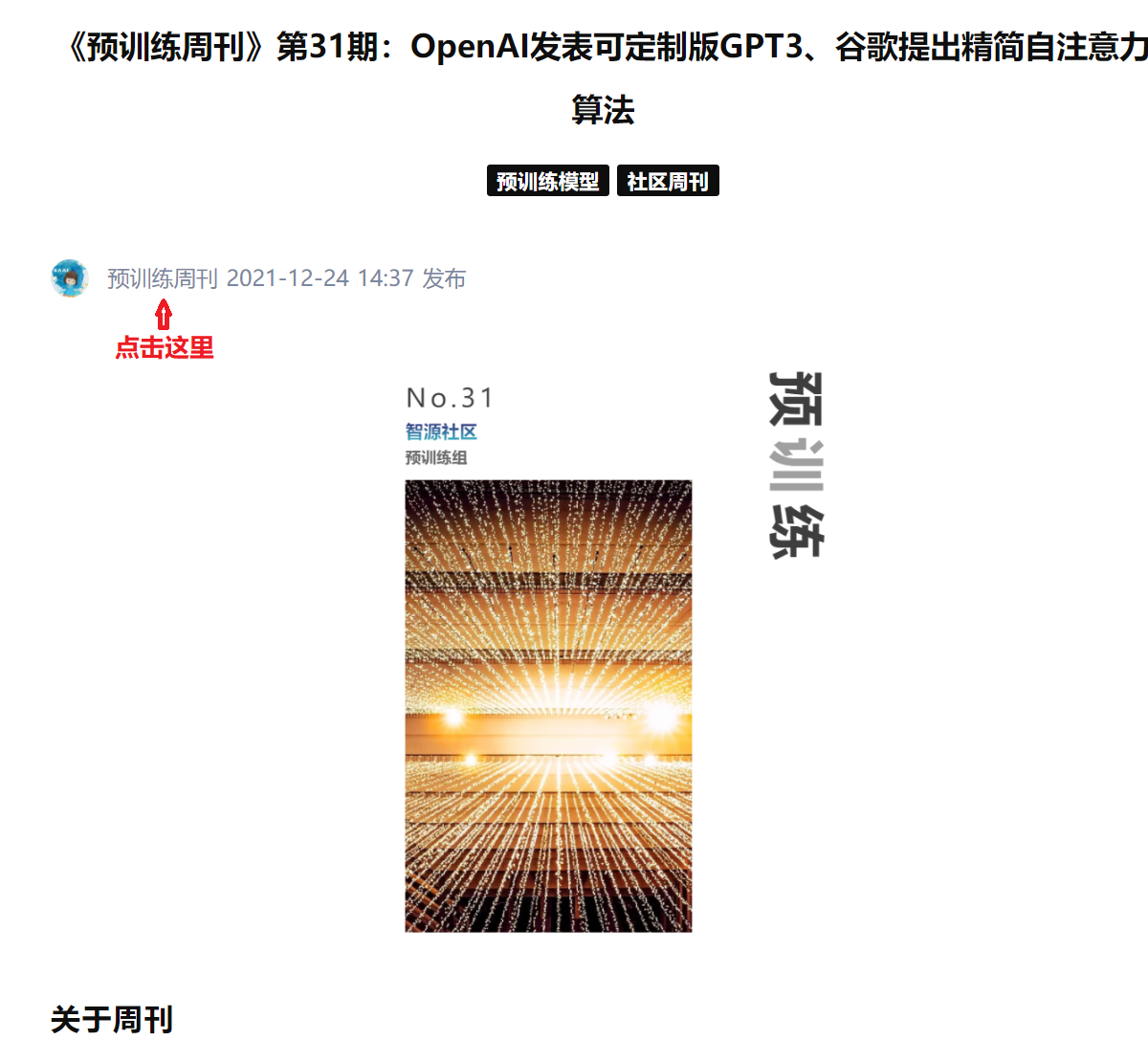
3,点击“关注TA”(如下图)
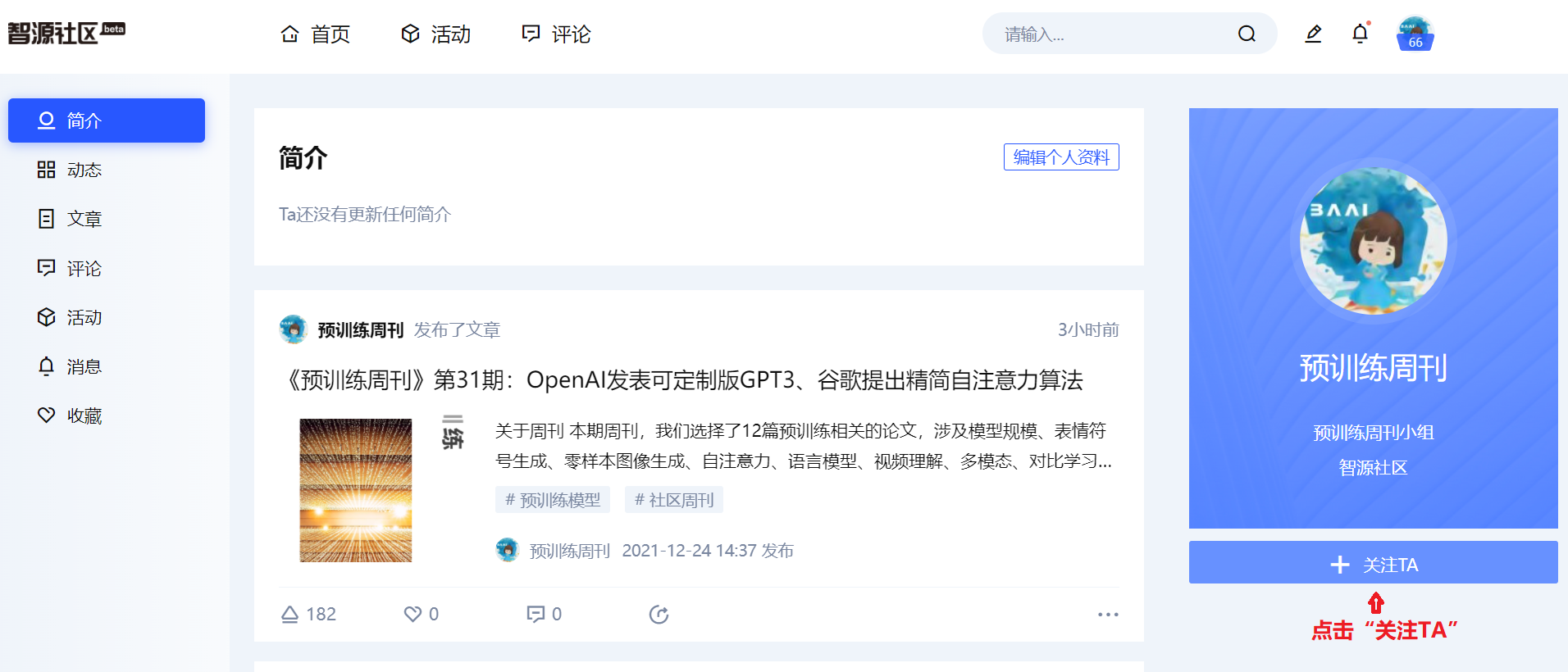
4,您已经完成《预训练周刊》订阅啦,以后智源社区自动向您推送最新版的《预训练周刊》!
【NLP研究】
标题:深圳先研院、阿里 | Unified Dialog Model Pre-training for Task-Oriented Dialog Understanding and Generation(以任务为导向的对话理解和生成的统一对话模型预训练)
作者:Wanwei He、Yongbin Li等
简介:本文提出了半监督预训练对话模型 SPACE。该模型将任务型对话中的任务流概念引入预训练模型架构中,采用单个统一的 Transformer 骨架将对话理解、对话策略和对话生成进行顺序建模,可以同时解决下游各种不同类型的任务型对话相关任务。本文为每个组件设计一个专门的预训练目标。具体来说,用span掩码语言建模对对话编码模块进行预训练,以学习语境化的对话信息。为了捕捉结构化的对话语义,本文在额外的对话注释的帮助下,通过一个新颖的树型诱导的半监督对比学习目标对对话理解模块进行预训练。此外,通过最小化其输出策略向量和响应的语义向量之间的L2距离来预训练对话策略模块,以实现策略优化。实验结果表明:SPACE 在意图识别、对话状态追踪、端到端对话建模对话任务,共计 8 个数据集上均取得了 SOTA 性能。
论文下载:https://dl.acm.org/doi/pdf/10.1145/3477495.3532069
阅读详情
标题:苏州大学、阿里 | SelfMix: Robust Learning Against Textual Label Noise with Self-Mixup Training(SelfMix: 利用自混合训练对文本标签噪声进行稳健学习)
作者:Dan Qiao、Min Zhang等
简介:本文提出了一种处理预训练中噪音的方法。传统的文本分类的成功依赖于注释数据,而预训练的语言模型的新范式仍然需要一些标签数据来完成下游任务。然而,在现实世界的应用中,标签噪声不可避免地存在于训练数据中,损害了在这些数据上构建的模型的有效性、可靠性和概括性。本文提出了SelfMix来处理文本分类任务中的标签噪声。SelfMix使用高斯混合模型来分离样本并利用半监督学习。与以前的工作不同的是,本文的方法利用单个模型的dropout机制来减少自训练中的确认偏差,并引入了一个文本级别的混合训练策略。在三个不同类型的文本分类基准上的实验结果表明,在不同的噪声比例和噪声类型下,本文的方法的性能优于这些为文本和视觉数据设计的强大基线。
论文下载:https://arxiv.org/pdf/2210.04525.pdf
阅读详情
标题:哥本哈根大学 | Are Pretrained Multilingual Models Equally Fair Across Languages?(多语言预训练模型在不同语言之间是否同样公平?)
作者: Laura Cabello Piqueras, Anders Søgaard
简介:本文基于业界首个“对不同语言的多语言模型的群体差异比较的数据集”进行了多语言模型公平性的研究。预训练的多语言模型可以帮助弥合数字语言鸿沟,为资源较低的语言提供高质量的NLP模型。到目前为止,对多语言模型的研究主要集中在性能、一致性和跨语言通用性方面。然而,随着它们在非主流地区和下游社会影响中的广泛应用,将多语言模型与单语模型置于同样的审查之下是很重要的。这项工作调查了多语言模型的公平性,旨在确认相关模型在不同语言之间是否同样公平。为此,作者创建了一个新的四维多语言平行完形填空测试示例数据集:MozArt,其包含测试参与者的人口统计信息。作者在MozArt上评估了三种多语言模型:mBERT、XLM-R和mT5。实验表明:在四种目标语言中,上述三种模型表现出不同程度的群体差异、并不公平(如德语的风险较高)。
论文下载:https://arxiv.org/pdf/2210.05457
阅读详情
标题:剑桥、格拉斯哥大学 | Can Pretrained Language Models (Yet) Reason Deductively?(预训练的语言模型:还可以演绎推理吗?)
作者:Zhangdie Yuan, Songbo Hu, Ivan Vulic´等
简介:本文研究预训练语言模型 (PLM) 是否具备良好的演绎推理能力。使用PLM获取事实知识已引起越来越多的关注,在许多知识密集型任务中已表现出可观的性能。这些任务的良好表现使社区相信这些模型确实具有一定的推理能力、而不仅仅是记忆知识。在本文中,作者对 PLM 的可学习演绎推理(即显式演绎推理)能力进行了全面评估。通过一系列对照实验,有两个主要发现:(1) PLM 不能充分概括学习到的逻辑规则,并且对简单的对抗性表面形式编辑执行不一致。
(2) 虽然 PLM 的演绎推理微调:确实提高了模型对“未见知识事实”推理的性能,但也导致灾难性地忘记以前学过的知识。实验结果表明:PLM 还不能执行可靠的演绎推理,这证明了受控检查和探索 PLM 推理能力的重要性。作者表明: PLM 距离人类水平的推理能力还很远,即使对于简单的演绎任务也是如此。
论文下载:https://arxiv.org/pdf/2210.06442
阅读详情
【CV研究】
标题:阿姆斯特丹大学、BrainCreator、牛津大学联合 | Prompt Generation Networks for Efficient Adaptation of Frozen Vision Transformers(有效适应冷冻视觉Transformer的Prompt生成网络)
作者: Jochem Loedeman, Maarten C. Stol, Tengda Han 等
简介:本文主要研究有效的视觉Prompt学习框架。Prompt学习已经成为一种灵活的方式来适应模型,只需学习额外的输入到一个保持冻结的模型,但到目前为止,性能仍然不如微调。为了解决这个问题,作者提出了Prompt提示生成网络(PGN):通过从学习的token库中采样来生成依赖于输入的Prompt提示。实验证明: PGN 在使预训练模型适应各种新数据集方面是有效的。PGN大大超过了以前的Prompt学习方法,甚至在 12 个数据集中的 5 个上进行了完全微调、而同时需要的参数减少了 100 倍。PGN 甚至可以用于同时对多个数据集进行训练和推断,并学习在域之间分配token。鉴于这些发现,作者得出结论:针对冷冻模型的下游任务,PGN 是一种可行且可扩展的方法!
论文下载:https://arxiv.org/pdf/2210.06466
代码下载:https://github.com/jochemloedeman/PGN
阅读详情
【基础研究】
标题:微软 | Foundation Transformers(基础Transformers)
作者:Hongyu Wang、Furu Wei等
简介:本文提出了一种通用Transformer架构。跨越语言、视觉、语音和多模态的模型架构的大融合正在出现。然而,在同一名称 "Transformer "下,上述领域使用不同的实现方式以获得更好的性能,例如:BERT使用Post-LayerNorm、而GPT和视觉Transform使用Pre-LayerNorm。本文呼吁为真正的通用模型开发基础Transformer,它可以作为各种任务和模式的首选架构,并保证训练的稳定性,为此引入了一个Transformer变体:名为Magneto,以实现这一目标。具体来说,本文提出了Sub-LayerNorm来实现良好的表达能力,并从理论上提出了DeepNet的初始化策略来实现稳定规模提升。实验证明了它比为各种应用设计的上的Transformer变体更出色的性能和更好的稳定性,包括语言建模(即BERT和GPT)、机器翻译、视觉预训练(即BEiT)、语音识别和多模态预训练(即BEiT-3)。
论文下载:https://arxiv.org/pdf/2210.06423v1.pdf
阅读详情
【地理信息研究】
标题:谷歌、佐治亚理工学院 | Transformer-based Localization from Embodied Dialog with Large-scale Pre-training(经Embodied Dialog大规模预训练的、基于Transformer的位置定位技术)
作者:Meera Hahn,James M. Rehg
简介:本文通过Embodied Dialog的位置定位技术 (LED) 解决了具有挑战性任务。给定来自两个代理的对话,一个在未知环境中导航的观察者和一个试图识别观察者位置的定位器,目标是预测观察者在地图中的最终位置。作者开发了一种新颖的 LED-Bert 架构并提出了一种有效的预训练策略。作者演示了LED泊位的预训练方案,该方案利用大规模网络数据以及其他多模态包含的AI任务数据来学习成功定位LED所需的视觉基础。实验表明:基于图形的场景表示比先前作品中使用的自上而下的 2D 地图更有效,LED Bert不仅实现了SOTA性能、而且显著优于其他学习基线。
论文下载:https://arxiv.org/pdf/2210.04864
阅读详情
【生命科学研究】
标题:麻省理工 |Machine Learning Optimization of Candidate Antibodies Yields Highly Diverse Sub-nanomolar Affinity Antibody Libraries(机器学习优化生成多样化亚纳摩尔级亲和力抗体库)
作者:Tristan Bepler, Matthew E. Walsh等
简介:本文将预训练适应度景观用于抗体高亲和力库生成。作者展示了一种端到端的基于贝叶斯优化及语言模型的方法来设计大型多样化的scFv库。具体而言本文在大量的蛋白质序列上进行语言模型的无监督式预训练,进行亲和力监督微调,并从训练好的序列-亲和力模型中构建基于贝叶斯的抗体适应度景观,然后通过贝叶斯优化验证进行抗体设计。在与传统定向进化方法的正面比较中,本文的方法产生的最佳scFv比定向进化的最佳scFv的亲和力提高了28.8倍,此外,在最成功的文库设计中,99%的设计scFv都比初始scFv有改进。本文方法并不假定候选scFv与靶标强烈结合,并且依赖于序列数据而不需要序列比对或靶标抗原结构,同时还可以结合疏水性、等电点等抗体性质预测方法,适用于任何靶标抗原的早期阶段的抗体开发。
论文下载:https://doi.org/10.1101/2022.10.07.502662
阅读详情
【工具资源】
标题:微信版大语言模型demo及API
简介:近日微信开放大语言模型WeLM及其API,该模型参数量百亿水平,特色为采用RoPE相对位置编码,与传统的固定位置编码相比能更好处理长文本;以及使用62k个处理后的token的SentencePiece并保留其中的空格和Tab,这样更有利于下游任务;针对76个数据集各人工撰写10-20个Prompt,将原任务中的文本关系的标签和输入信息转化成流畅通顺的自然语言形式,更符合自回归语言模型的训练形式。实验结果显示,它在18个中文语言任务里,效果堪比参数量是其25倍的模型。通过API申请后可以直接使用,API链接及使用代码见下侧链接。
API申请链接:https://welm.weixin.qq.com/docs/api/
阅读详情
【观点分享】
标题:起底NLP“大一统”模型:UIE统一信息抽取框架背后的技术本质、收益辨析及几点思考
作者:刘焕勇
简介:UIE模型是百度今年开源出来的可以应用于zero-shot的新模型,其功能强大使用简便,虽不至于将NLP带入一个新的阶段,但也确实极大的降低了NLP基础任务的工程化使用门槛,是一个非常有效的工具。近期花了一些时间来阅读UIE的源码和论文,也做了一些实践,看了许多文章,作为总结性的文档,本文从读UIE源码后的一点感受,围绕到底是哪个UIE、paddle和原版的UIE、UIE真是大一统么以及UIE为什么有效等几个方面进行介绍,供大家参考。
阅读详情
欢迎加入预训练社群
如果你正在从事或关注预训练学习研究、实现与应用,欢迎加入“智源社区-预训练-交流群”。在这里,你可以:
-
学习前沿知识、求解疑难困惑
-
分享经验心得、展示风貌才华
-
参与专属活动、结识研究伙伴
请扫描下方二维码加入预训练群(备注:“姓名+单位+预训练”才会验证进群哦)

内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢