
本文为2022年最受智源社区小伙伴喜爱的文章,根据文章质量和热门程度等维度计算得出,还有AI大佬的全年总结盘点总结,也一并推荐给你。

智源社区特别推荐
智源社区最热文章推荐
1)AI具备创造力入选Science年度十大科学突破
推荐理由:AI具备创造力(AI gets creative)入选2022年十大科学突破(Breakthrough of the Year),涵盖了今年AI领域的重要成果AIGC和AI for Science:DALL-E为代表的文生图模型;AI设计蛋白质;AlphaTensor为代表的算法设计系统;AlphaCode为代表的AI编程系统。

Science|DeepMind推出AlphaCode
论文地址:https://www.deeplearning.ai/the-batch/competitive-coder/
推荐理由:这是一款用 12 种编程语言对 8600 万个程序进行预训练的 Transformer,并针对编码竞赛的内容进行了微调。通过推理,它产生了一百万种可能的解决方案,并过滤掉了不佳的解决方案。通过这种方式,它在 10 次编程竞赛中击败了一半以上的参赛者。
推荐理由:提出一种新型的上下文自编码模型,可以预测不同患者对药物的特异性反应。在传统模式下,新药从开发、试验、到完全上市,中间需要近10年的时间,而AI能够利用数据进行预测,将大幅缩短新药上市时间,降低成本。
论文地址:https://www.nature.com/articles/s42256-022-00541-0
(两篇论文)
论文地址1:https://www.science.org/doi/10.1126/science.add2187
论文地址2:https://www.science.org/doi/10.1126/science.add1964
5)Science|DeepMind的AI智能体DeepNash战胜专业级人类玩家
DeepNash 使用了一种博弈论的、无模型的深度强化学习方法 R-NaD,无需搜索,便能以从头开始的自我博弈方式来学习如何掌握游戏策略。
论文地址:www.science.org/doi/10.1126/science.add4679
6)Nature|DeepMind推出AlphaTensor
推荐理由:

7) DeepMind :AlphaZero 的黑箱打开了
推荐理由:Demis Hassabis 与 DeepMind 的同事以及谷歌大脑的研究员合作了一项研究,在 AlphaZero 的神经网络中找到了人类国际象棋概念的证据,展示了网络在训练过程中获得这些概念的时间和位置,并发现 AlphaZero 与人类不同的下棋风格。该论文已发表于 PNAS。
论文地址:https://www.pnas.org/doi/epdf/10.1073/pnas.2206625119
8)POINT-E:OpenAI开源文本生成点云系统,单GPU迅速生成3D模型
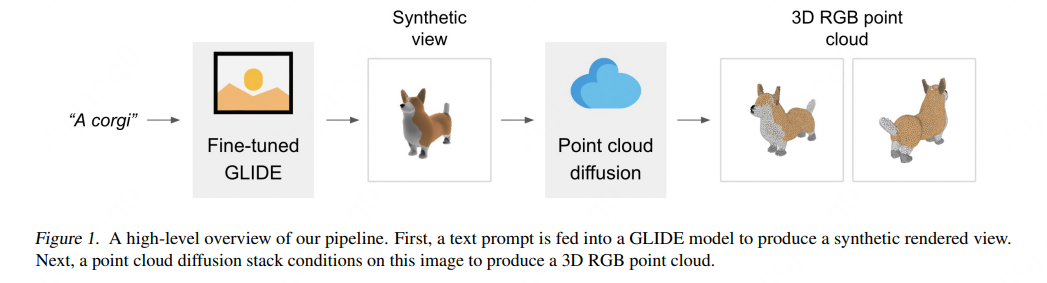
推荐理由:
论文探索一种替代性3D物体生成方法,该方法在单个GPU上只需1-2分钟就能生成3D模型。所提出方法首先使用文本到图像的扩散模型生成一个单一的合成视图,然后使用第二个扩散模型生成一个3D点云,该模型以生成图像为条件。虽然该方法在采样质量方面仍未达到最先进的水平,但采样速度要快一到两个数量级,为一些使用情况提供了实际的权衡。
论文地址:https://arxiv.org/abs/2212.08751
模型试用:https://huggingface.co/spaces/openai/point-e
提出具身图灵测试(The Embodied Turing Test )作为 NeuroAI 的终极挑战,核心在于高级感觉运动能力,具体包括与世界互动、动物行为的灵活性、能源效率等特征。还设想了应对具身图灵测试的路线,从进化史角度把 AI 系统的具身图灵测试分解为从中低级生物进阶到更复杂生物的智能。
推荐理由:作者是剑桥大学的两位研究人员Nathan Benaich 和 Ian Hogarth。State of AI的人工智能年度报告系列由行业和研究领域的领先人工智能从业者审查,包括科研、产业、政治、安全性、预测五个方向:新的独立研究实验室正在迅速开源主要实验室的闭源输出;主要 AI 研究实体的安全意识;中美人工智能研究差距持续扩大;人工智能驱动的科学研究继续带来突破。
推荐理由:吴恩达在其创办的人工智能周刊《The Batch》上更新了一篇博文,总结了机器学习领域多个基础算法的历史溯源,以及机器学习模型的核心思想。调研了六种基础算法以及详细说明:线性回归、逻辑回归、梯度下降、神经网络、决策树与k均值聚类算法。

13)符尧:追溯ChatGPT各项能力的起源
推荐理由:
初代GPT-3模型通过预训练获得生成能力、世界知识和in-context learning,通过instruction tuning的模型分支获得了遵循指令和能泛化到没有见过的任务的能力。结合这两个分支,code-davinci-002似乎是具有所有强大能力的最强GPT-3.5模型。接下来通过有监督的instruction tuning和 RLHF通过牺牲模型能力换取与人类对齐,即对齐税。RLHF 使模型能够生成更翔实和公正的答案,同时拒绝其知识范围之外的问题。
推荐理由:UC伯克利教授、深度学习专家Pieter Abbeel在其播客节目《机器人大脑》(Robot Brains)中,对Geoffrey Hinton进行了一次访谈。

Hinton讲述了他从学术界到谷歌大脑的工作经历、学习心理学和当木匠的经历,以及可视化技术t-SNE算法背后的历史,并就一些问题发表了他的观点,包括:现有的神经网络和反向传播算法与大脑的运作方式有何不同;为什么我们需要无监督的局部目标函数;睡眠和玻尔兹曼机的功能是什么;为什么培育计算机比制造计算机更好?为什么需要负面数据;如今的大规模语言模型是否真正理解了语言。
视频地址:https://www.youtube.com/watch?v=2EDP4v-9TUA
推荐理由:本文作者Daniel Jeffries,是Stability AI(研发Stable Diffusion的公司) 的首席信息官,他分享了我们正处于一个转折点这一鲜明话题:Stable Diffusion是第一个以开源形式发布的真正先进的模型,该模型在超级计算机上使用4000个A100s芯片进行训练,它标志着人工智能的下一个转折点:开放基础模型(foundation models)的时代的到来。

17)Andrej Karpathy关于AGI、Optimus、软件2.0时代访谈
推荐理由:在著名AI播客主持人Lex Fridman长达三个小时的访谈节目中,谈及了他对于Transformer、神经网络、大规模语言模型、AGI的理解,以及对特斯拉、Optimus的看法。他还讲到了对宇宙人生、外星生物的畅想,以及包括他个人专注、近乎疯狂的日常工作模式,对
视频地址:https://www.youtube.com/watch?v=cdiD-9MMpb0
18)OpenAI CEO Sam Altman谈DALL•E 2的更深远影响
推荐理由:OpenAI CEO Sam Altman带你看DALL•E 2精华内容整理。Sam认为一个新的计算机界面趋势即将形成的例子:你用自然语言或上下文线索说出想要的东西,计算机就会去做。我们为代码和现在的图像生成提供了这种服务;这两种服务都会变得更好。以及对Copilot理解:是一个帮助编码员提高生产力的工具,但离能够创建一个完整的程序仍然很远。DALL-E 2是一个能帮助艺术家和插图画家更有创造力的工具,但它也能创造一个 "完整的作品"。
原文地址:https://blog.samaltman.com/dall-star-e-2
论文总引用量已超过10万次,Edward H. Sargent分享「写论文10大技巧」
推荐理由:学术大牛Edward H. Sargent为多伦多大学电子和计算机工程系教授,还是加拿大皇家科学院院士、加拿大工程院院士。截至目前,Sargent教授已发表16篇Nature和14篇Science。而且除了30篇正刊之外,他发表的Nature系文章高达139篇。据谷歌学术统计,他的论文总引用量已超过100000次。文章分享了10点关于写、发论文的锦囊妙计。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢