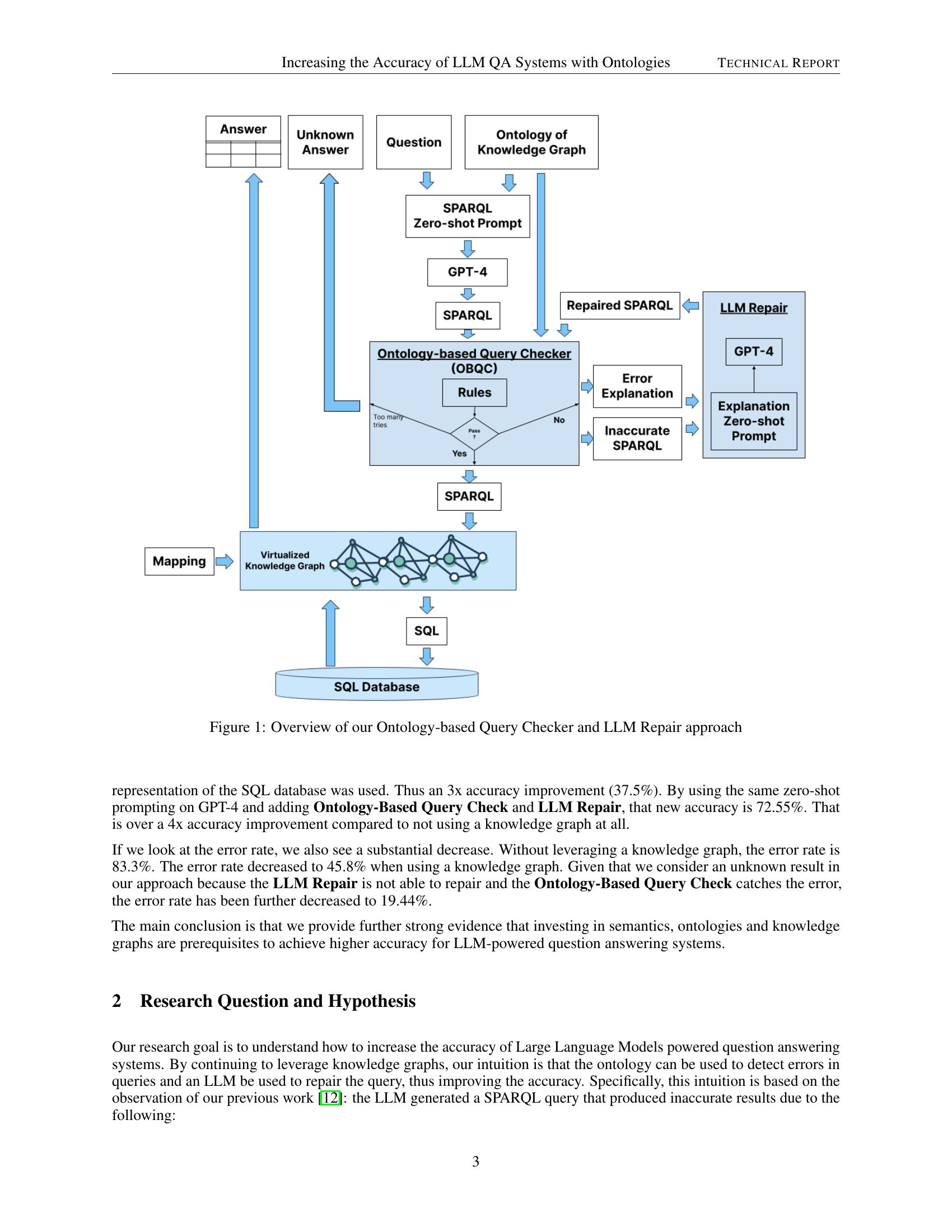
检索在推荐系统、搜索和自然语言处理中扮演着基础性的角色,通过在大语料库中高效地查找相关项以响应查询。由于最大内积搜索(MIPS)实现了基于点积的高效检索,因此点积已广泛用作检索任务中的相似度函数。然而,最先进的检索算法已经转向学习相似度。这些算法的形式各不相同,可以使用多个嵌入来表示查询,可以部署复杂的神经网络,可以使用波束搜索直接从查询中解码项目 ID,并可以将多种方法结合成混合解决方案。不幸的是,在这些最先进的设置中,我们缺乏高效的检索解决方案。我们的工作研究了使用学习相似度函数的近似最近邻搜索技术。我们首先证明混合逻辑斯蒂回归(MoL)是一种通用的逼近器,可以表示所有学习的相似度函数。接下来,我们提出了使用MoL检索近似前K个结果的技术,并提供了紧密的界限。最后,我们将我们的技术与现有方法进行比较,结果显示MoL在推荐检索任务上设置了新的最先进结果,我们使用学习相似度的近似前K个检索优于基线,延迟高达两个数量级,同时实现了准确算法的> .99召回率。