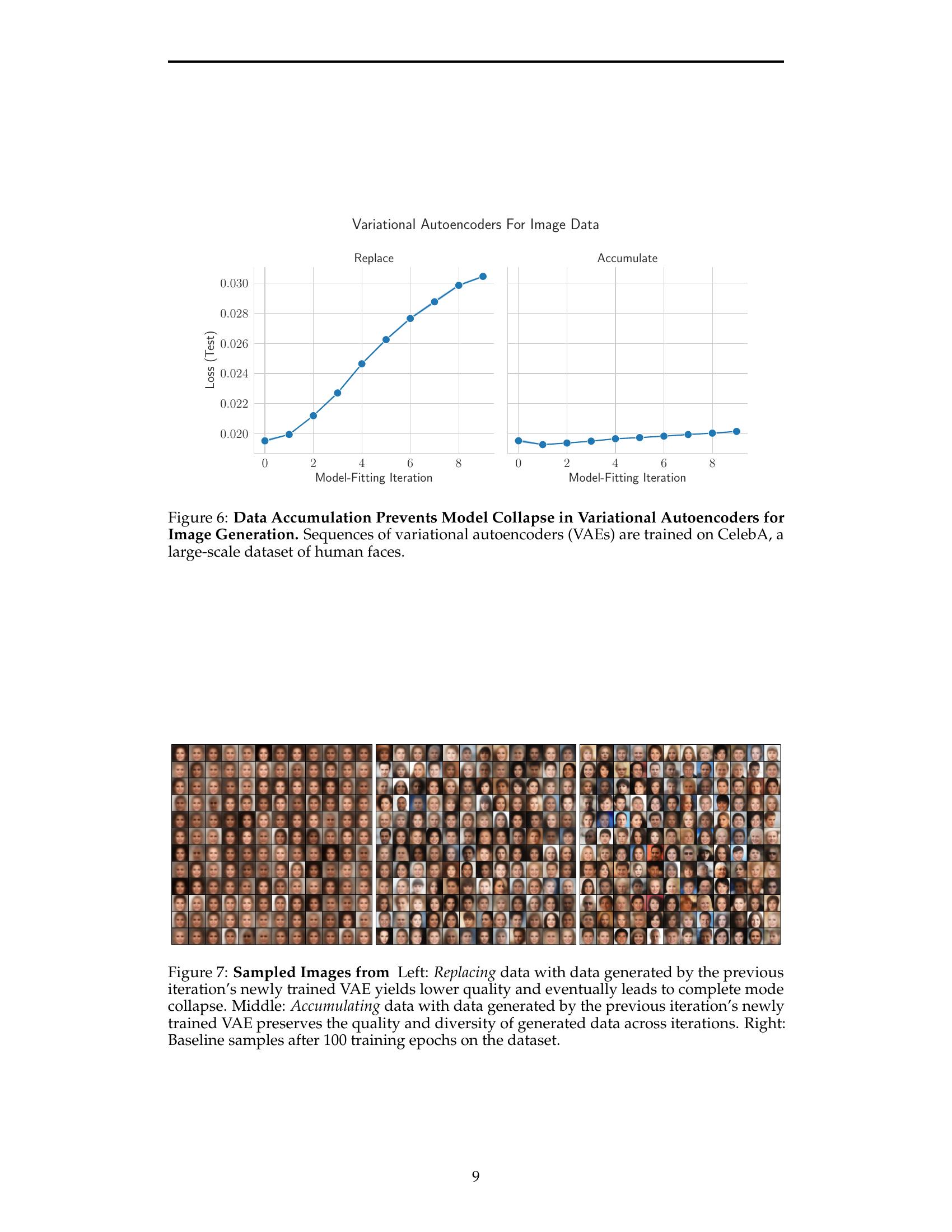
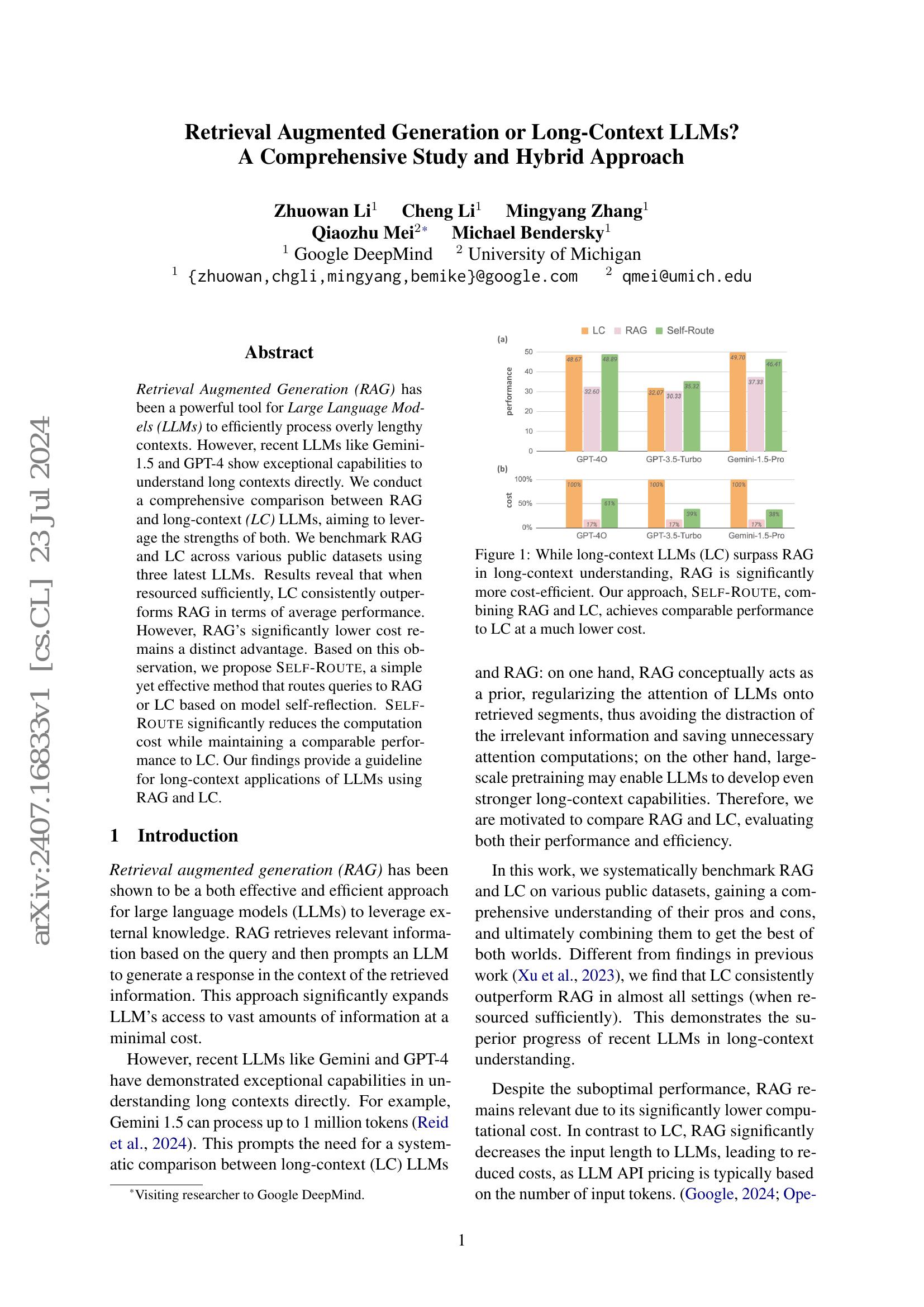
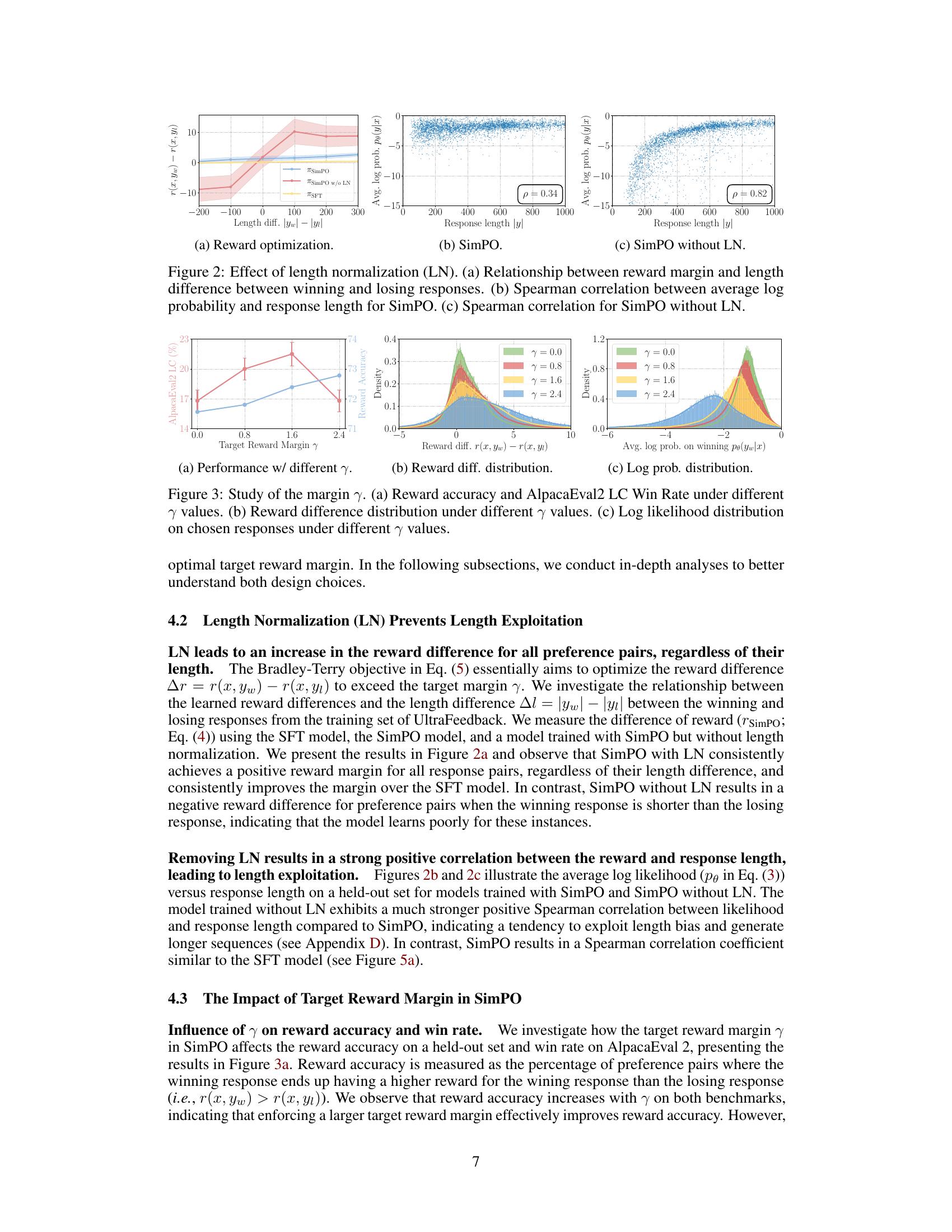
随着生成模型的不断涌现,加上在网络规模数据上的预训练,一个及时的问题浮现:当这些模型用自己生成的输出进行训练时会发生什么?最近的研究发现,模型和数据之间的反馈循环可能导致模型崩溃,即性能随着每次模型拟合迭代而逐渐降低,直到最新的模型变得无用。然而,最近几篇研究模型崩溃的论文假设新数据随时间取代旧数据,而不是假设数据随时间积累。在本文中,我们比较这两种情况,并表明积累数据可以防止模型崩溃。我们首先研究一个分析可追踪的设置,其中一系列线性模型适合于之前模型的预测。以前的工作表明,如果数据被替换,测试误差随着模型拟合迭代次数的增加呈线性增长;我们通过证明,如果数据积累,测试误差具有独立于迭代次数的有限上界来扩展这个结果。接下来,我们通过在文本语料库上预训练语言模型序列来实验性地测试积累数据是否同样可以防止模型崩溃。我们证实,替换数据确实会导致模型崩溃,然后证明积累数据可以防止模型崩溃;这些结果适用于各种模型大小、架构和超参数。我们进一步展示,在真实数据上,类似的结果也适用于其他深度生成模型:用于分子生成的扩散模型和用于图像生成的变分自编码器。我们的工作提供了一致的理论和实证证据,证明了数据积累可以缓解模型崩溃。