本期周刊,我们选择了10篇预训练相关的论文,涉及语音表征、语音处理、大语言模型、语言分割、终身学习、可解释性、实体链接、医学文本、蛋白序列比对和多语言文档训练的探索。此外,在研究动态方面,我们选择了4篇预训练资讯,将介绍AI回顾、大模型回顾、数据集蒸馏和事实增强方面的一些最新内容。
周刊采用社区协作的模式产生,欢迎感兴趣的朋友们参与我们的工作,一起来推动预训练学习社群的分享、学习和交流活动。可以扫描文末的二维码加入预训练群。
(本期贡献者:申德周 翟珂 吴新刚)
关于周刊订阅
告诉大家一个好消息,《预训练周刊》开启“订阅功能”,以后我们会向您自动推送最新版的《预训练周刊》。订阅方法:
1,注册智源社区账号
2,点击周刊界面左上角的作者栏部分“预训练周刊”(如下图),进入“预训练周刊”主页。
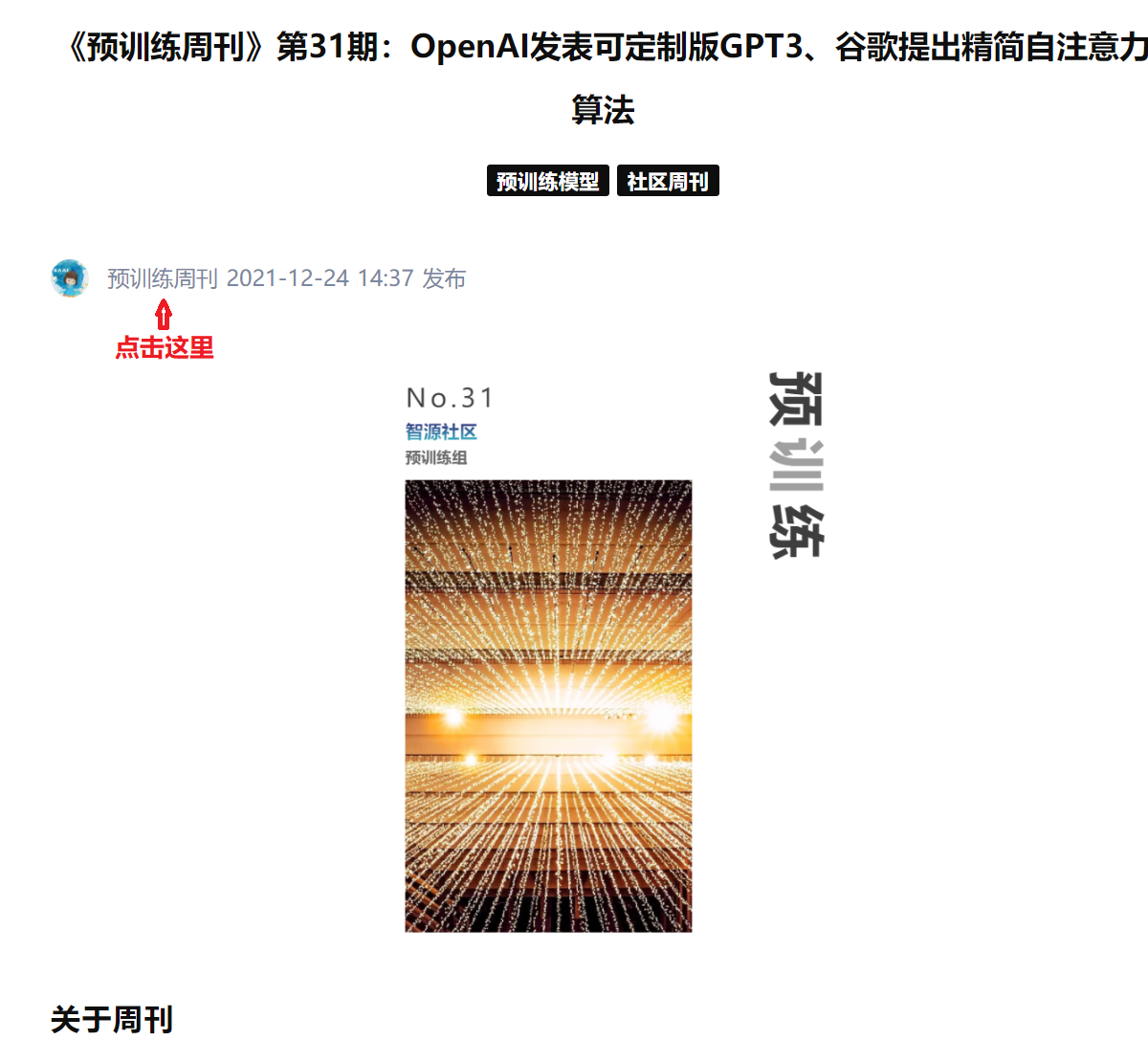
3,点击“关注TA”(如下图)
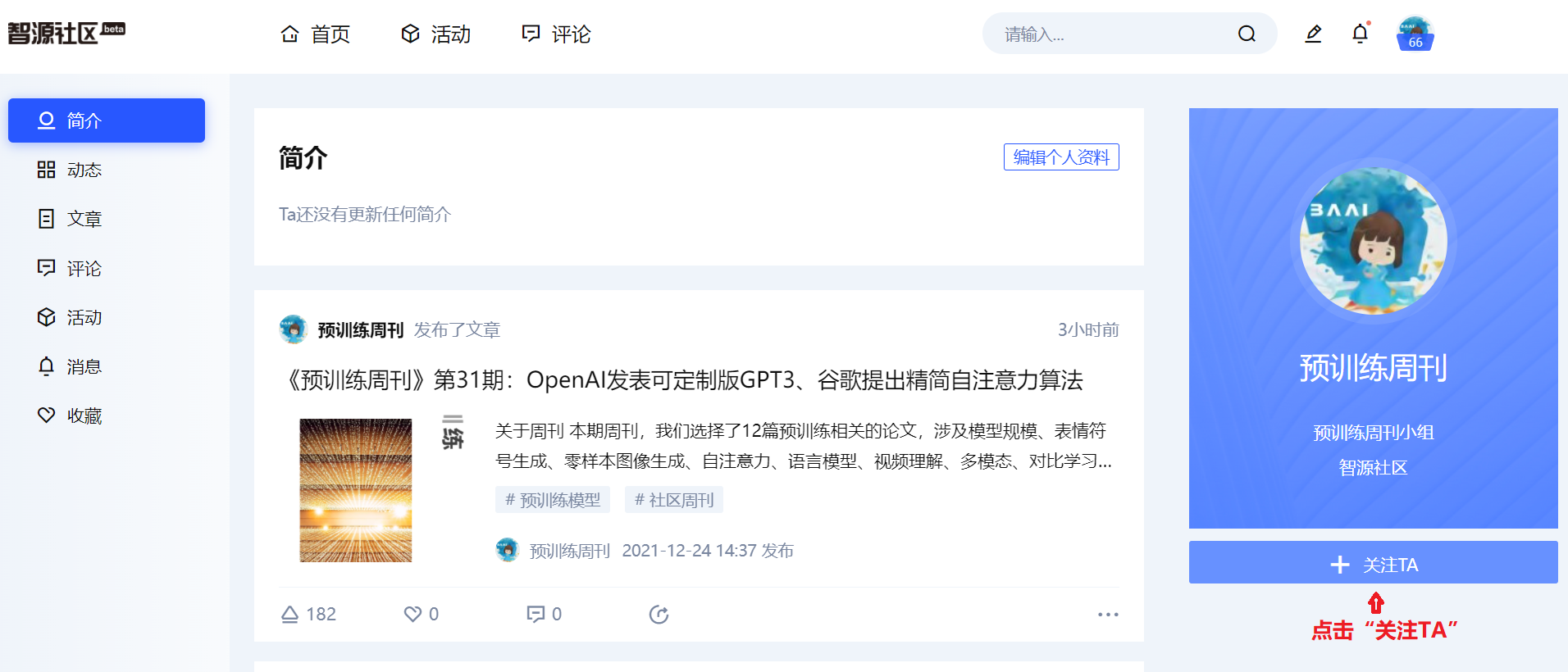
4,您已经完成《预训练周刊》订阅啦,以后智源社区自动向您推送最新版的《预训练周刊》!
论文推荐
标题:Meta、Google、Outreach等|XLS-R: SELF-SUPERVISED CROSS-LINGUAL SPEECH REPRESENTATION LEARNING AT SCALE(XLS-R:自监督跨语言语音大规模表示学习)
作者:Arun Babu, Changhan Wang, Michael Auli等
简介:本文介绍了基于wav2vec 2.0的大规模跨语言语音表示学习。作者基于近50万小时的128种语言的公开语音音频,训练最多20亿个参数模型,公开数据比已知最大的先前工作多出一个数量级。作者的评估涵盖了广泛的任务、领域、数据机制和语言,无论是高和低资源。在CoVoST-2语音翻译基准上,作者改进了在21个翻译方向上平均7.4BLEU得分。对于语音识别,XLS-R 改进了在 BABEL、MLS、CommonVoice 以及VoxPopuli上最著名的先验工作,降低平均相对14-34%错误率。XLS-R还设置了VoxLingua107语言识别的最新技术。
代码下载:
https://www.github.com/pytorch/fairseq/tree/master/examples/wav2vec/xlsr
论文下载:
https://arxiv.org/pdf/2111.09296v3.pdf
阅读详情
标题:微软|WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing(WavLM:大规模自监督预训练用于全栈语音处理)
作者:Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu等
简介:本文介绍了基于自监督学习在语音识别的应用。作者提出了一种新的预训练模型 WavLM,以解决全栈下游语音任务。WavLM 扩展了HuBERT去噪掩码语音建模的框架,其中目标是预测伪标签掩蔽区域上的模拟嘈杂语音。通过添加额外的噪音或来自其他话语的语音来创建关于原话的模拟语音。去噪蒙版语音建模任务旨在改进模型对复杂声学环境的鲁棒性和保留说话人的身份。作者扩大规模训练数据集从60k小时到 94k小时。WavLM Large在SUPERB基准测试中实现了最先进的性能,并带来了各种语音处理任务在其代表性基准上的显着改进。
代码下载:
https://github.com/microsoft/unilm/tree/master/wavlm
论文下载:
https://arxiv.org/pdf/2110.13900.pdf
阅读详情
标题:百度、鹏城实验室|ERNIE 3.0 Titan: Exploring Larger-scale Knowledge Enhanced Pre-training for Language Understanding and Generation(ERNIE 3.0 Titan:探索更大规模的知识增强型语言理解和生成预训练)
作者:Shuohuan Wang, Yu Sun, Yang Xiang, Haifeng Wang
简介:本文介绍了一个中文大语言模型。作者提出了名为ERNIE 3.0的统一框架,用于预训练大规模知识增强模型,并训练了一个具有 100 亿个参数的模型。 ERNIE 3.0 在各种 NLP 任务上的表现优于最先进的模型。为了探索扩展 ERNIE 3.0 的性能,作者在PaddlePaddle平台上训练了具有多达2600亿个参数的百亿参数模型 ERNIE 3.0 Titan。为了减少计算开销和碳排放,作者为 ERNIE 3.0 Titan 提出了一个在线蒸馏框架,其中教师模型将同时教授学生和自我训练。ERNIE 3.0 Titan是迄今为止最大的中文密集预训练模型。实证结果表明,ERNIE 3.0 Titan在 68 个NLP数据集上的表现优于最先进的模型。
论文下载:
https://arxiv.org/pdf/2112.12731v1.pdf
阅读详情
标题:越南信息技术大学 | Joint Chinese Word Segmentation and Part-of-speech Tagging via Two-stage Span Labeling(基于两阶段跨度标注的汉语联合分词和词性标注)
简介:本文讲述了对中文分词基于bert模型研究的新成果。解决歧义和检测未知词是中文分词和词性标注这一领域的挑战性问题。以往对汉语分词和词性标注的联合研究主要遵循基于字符的标注模型、重点是对n-gram特征进行建模。与之前的研究工作不同,作者提出了SpanSegTag神经模型---用于汉语分词和词性标注,其中每个n-gram作为单词和词性标注的概率是主要问题。在连续字符的左右边界表示上,作者使用biaffine操作来建模n-gram。实验表明:基于BERT的模型SpanSegTag取得了显著的改进。
论文下载:
https://arxiv.org/pdf/2112.09488.pdf
阅读详情
标题:卡内基梅隆大学、蒙特利尔大学等 | An Empirical Investigation of the Role of Pre-training in Lifelong Learning(预训练在终身学习中的作用的实证研究)
简介:本文研究预训练对终身学习中灾难性遗忘的影响。作者在预先训练的大型模型中研究现有方法,并评估这些模型在各种文本和图像分类任务中的性能,包括基于15种不同NLP任务的新数据集进行的大规模研究。实验表明:与随机初始化的模型相比,通用预训练隐式地减轻了顺序学习多个任务时灾难性遗忘的影响。作者还进一步通过分析损失情况研究预先训练可以减轻遗忘的原因,实验发现预训练的权重应通过导致更大的极小值来缓解遗忘。因此作者提议联合优化当前任务损失和损失盆地锐度,以便在顺序微调期间明确鼓励更宽的盆地。实验表明该优化方法可在多个环境中实现与最先进的任务顺序连续学习相媲美的性能、而不会保留随任务数量而扩展的内存。
论文下载:
https://arxiv.org/pdf/2112.09153.pdf
阅读详情
标题:卡内基梅隆大学、谷歌 | Explain, Edit, and Understand: Rethinking User Study Design for Evaluating Model Explanations(解释、编辑和理解:对评估模型解释的用户研究设计的再思考)
简介:本文为解释机器学习模型的预测,研究人员提出了数百种将预测归因于重要特征的技术。作者进行了一项众包研究:参与者与欺骗检测模型互动,该模型经过训练、能够区分真假酒店评论。当前面临的挑战是在新评论上模拟模型以及编辑评论、以降低最初预测的类的概率(成功的操纵,将导致一个截然相反的案例)。在训练阶段而非测试阶段,输入范围会突出显示、以能传达显著性。通过作者的评估:实验观察到与无解释控制相比、对于线性词袋模型、在训练期间能够访问特征系数的参与者能够在测试阶段导致模型置信度的更大降低。对基于BERT的分类器,流行的局部解释并不能提高其在无解释情况下降低模型可信度的能力。值得注意的是,当通过一个线性模型的(全局)属性来解释BERT模型时,人们可以有效地操纵该模型。
论文下载:
https://arxiv.org/abs/2112.09669
阅读详情
标题:cisco | Evaluating Pretrained Transformer Models for Entity Linking in Task-Oriented Dialog(在面向任务的对话框中评估用于实体链接的预训练 Transformer 模型)
简介:在面向任务的对话无监督实体链接的角度,本文重点评估了不同预训练模型的文本短语理解能力。作者从面向任务的对话中的无监督实体链接的角度评估不同的 PTM,跨越了5 个特征:句法、语义、短格式、数字和语音。根据作者的研究成果:(1)与传统技术相比,尽管与其他神经基线相比具有竞争力,但部分PTM 产生了低于标准的结果。(2)PTM的部分缺点可以通过使用针对文本相似性任务进行微调来解决,这说明在理解语义和句法对应方面的能力有所提高;(3)定性分析预测中的细微差别,并讨论进一步改进的范围。
代码下载:
https://github.com/murali1996/el_tod
论文下载:
https://arxiv.org/pdf/2112.08327.pdf
阅读详情
标题:微软|Fine-Tuning Large Neural Language Models for Biomedical Natural Language Processing(用于生物医学自然语言处理的大型神经语言模型微调)
作者:Robert Tinn, Hoifung Poon 等
简介:本文提出了一项关于生物医学NLP应用的大型神经语言模型微调的综合研究。作者表明,微调的不稳定性在低资源的生物医学任务中普遍存在,并且在不同的预训练设置和更大模型中进一步加剧。在对优化调整和特定层适应技术的彻底评估中,作者确定了微调稳定的最佳做法,为生物医学NLP的BLURB基准建立了新的技术状态。具体来说,冻结较低的层对标准的BERT-base模型有帮助,而层间衰减对BERT-large和ELECTRA模型更有效。对于文本相似性任务,重新初始化顶层是最佳策略。总的来说,特定领域的词汇和预训练有利于更稳健的模型进行微调。另外本文探讨了未来的方向,包括应用于其他生物医学任务,探索临床NLP中的微调稳定性,进一步研究实际使用案例中的模型修剪和压缩等。
论文下载:
https://arxiv.org/abs/2112.07869v1
阅读详情
标题:港中文、微软等|fastMSA: Accelerating Multiple Sequence Alignment with Dense Retrieval on Protein Language(fastMSA: 在蛋白质语言上用稠密检索法加速多重序列比对)
作者:Liang Hong, Yu Li 等
简介:进化相关的序列为蛋白质的结构和功能提供了信息。多重序列比对,包括从大型数据库中搜索同源物和序列比对,可以有效地挖掘信息,帮助蛋白质结构和功能的预测。本文提出了一种新的方法,即fastMSA,以显著提高其速度。本文提出了一个新颖的双编码器架构,利用基于BERT的蛋白质语言模型,可以将蛋白质序列嵌入到一个低维空间,并在运行BLAST之前有效地过滤不相关的序列。实验结果表明,本文可以以34倍的速度召回大部分的同源物。此外,本文的方法与下游任务兼容,如使用AlphaFold进行结构预测。使用本文的方法生成的比对结果,在蛋白质结构预测方面的性能几乎没有受到影响,而且运行时间更短。fastMSA将有效地帮助基于同源物和多序列比对的蛋白质序列、结构和功能分析。
论文下载:
https://doi.org/10.1101/2021.12.20.473431
阅读详情
标题:华盛顿大学、谷歌|DOCmT5: Document-Level Pretraining of Multilingual Language Models(DOCmT5:多语言模型的文档级预训练)
作者:Chia-Hsuan Lee, Aditya Siddhant, Viresh Ratnakar, Melvin Johnson
简介:本文介绍了DOCmT5,一个用大规模平行文档预训练的多语言序列对序列语言模型。虽然以前的方法主要是利用句子级的平行数据,但作者试图建立一个通用的预训练模型,可以理解和生成长文档。作者提出了一个简单有效的预训练目标,文档重排机器翻译(DrMT),其中任务为翻译经过重洗和屏蔽的输入文档。DrMT在各种文档级生成任务上为基线模型带来了较高的改进,本文还在WMT20 De-En和IWSLT15 Zh-En两个较竞争性的文档翻译任务中取得了最先进的效果。作者还对文档预训练的各种因素进行了广泛的分析,包括预训练数据质量的影响和结合单语种和跨语种预训练的影响。
论文下载:
https://arxiv.org/abs/2112.08709v1
阅读详情
标题:吴恩达|2021年终回顾
简介:吴恩达在最新发布的《The batch》中,撰文盘点了2021年全球人工智能的主要进展和趋势,内容包括:多模态、大模型、Transformer架构、AI语音生成,以及各国法律监管等。
阅读详情
标题:Will Douglas Heaven| 2021年是超大AI模型年
简介:2021是超大型AI模型的一年。这种趋势不仅仅发生在美国,美国初创公司 AI21 Labs 于 9 月推出的商用大型语言模型 Jurassic-1 以 1780 亿个参数略胜 GPT-3。 DeepMind 12 月发布的新模型 Gopher 有 2800 亿个参数。威震天-图灵 NLG 有 5300 亿。谷歌的 Switch-Transformer 和 GLaM 模型分别有 1 个和 1.2 万亿个参数。在中国,科技巨头华为构建了一个名为盘古的 2000 亿参数语言模型。另一家中国公司浪潮建立了源1.0,一个 2450 亿参数的模型。百度和深圳的一家研究机构鹏程实验室宣布了PCL-BAIDU Wenxin,这是一个拥有2800亿个参数的模型,百度已经在各种应用中使用,包括互联网搜索、新闻摘要和智能音响。而北京人工智能研究院发布了悟道2.0,拥有1.75万亿个参数。
阅读详情
标题:Google | Dataset distillation enables ML models to be trained using less data and compute(数据集蒸馏:实现高效地训练机器学习模型的新方法)
简介:本文研究通过对数据集蒸馏提炼实现训练机器学习模型效能的提升。作者重点研究另一种选择:“数据集蒸馏”的新方法,即将大型数据集提炼成一个合成的、较小的数据集,使用经蒸馏提炼的数据集训练模型将可以减少所需的内存和计算。作者基于“深度神经网络的无限宽度极限理论”,通过两种新的数据集蒸馏算法:核心诱导点与标签求解,实现了数据集的蒸馏提炼,并在基准图像分类数据集上实现了最先进的性能。特别是在CIFAR-10分类任务上:尽管有限宽度的ConvNet神经网络(1)仅使用10张图像:就实现了50%的测试精度;(2)使用500张图像实现了68%的测试精度;但最终仍然获得了最先进的结果。
阅读详情
标题:OpenAI | WebGPT: Improving the factual accuracy of language models through web browsing(WebGPT:通过浏览网络提高语言模型的事实准确性)
作者:Jacob Hilton、Suchir Balaji、Reiichiro Nakano、John Schulman
简介:近日,OpenAI发表了有关学习人类反馈的WebGPT的文章。研究人员对GPT-3进行了微调,以更准确地回答基于网络浏览器文本的开放式问题。该系统原型复制了人类在网上研究问题答案的方式,即提交搜索查询,跟踪链接,并向上和向下滚动网络页面。模型被训练要求能够引用答案来源,这使得它更容易提供反馈以提高事实的准确性。该模型是从GPT-3开始进行微调的。首先训练模型来复制人类的演示,这使它有能力使用基于文本的浏览器来回答问题。然后,通过训练一个奖励模型来预测人类的偏好,并使用强化学习或拒绝采样对其进行优化,从而提高模型答案的帮助性和准确性。该工作表明人类的反馈和工具,如网络浏览器,为实现强大的真实的、通用的人工智能系统提供了一条有希望的道路。
资讯链接:
https://openai.com/blog/improving-factual-accuracy/#samples
阅读详情
欢迎加入预训练社群
如果你正在从事或关注预训练学习研究、实现与应用,欢迎加入“智源社区-预训练-交流群”。在这里,你可以:
-
学习前沿知识、求解疑难困惑
-
分享经验心得、展示风貌才华
-
参与专属活动、结识研究伙伴
扫描下方二维码,或点击阅读原文申请加入(选择“兴趣交流群→预训练”)




评论
沙发等你来抢