
关于周刊
本期周刊,我们选择了11篇预训练相关的论文,涉及多模态生成、模型推理、多模态蒸馏、命名实体识别、图像分割、迁移学习、事实提取、蛋白结构、蛋白质表示、抗体性质和蛋白质性质的探索。此外,在研究动态方面,我们选择了5篇预训练资讯,将介绍文本表征、神经网络结构、大模型评价、模型训练和多模态学习方面的一些最新内容。
周刊采用社区协作的模式产生,欢迎感兴趣的朋友们参与我们的工作,一起来推动预训练学习社群的分享、学习和交流活动。可以扫描文末的二维码加入预训练群。
(本期贡献者:申德周 翟珂 吴新刚)
关于周刊订阅
告诉大家一个好消息,《预训练周刊》开启“订阅功能”,以后我们会向您自动推送最新版的《预训练周刊》。订阅方法:
方式一:
扫描下面二维码,进入《预训练周刊》主页,选择“关注TA”。

方式二:
1,注册智源社区账号
2,点击周刊界面左上角的作者栏部分“预训练周刊”(如下图),进入“预训练周刊”主页。
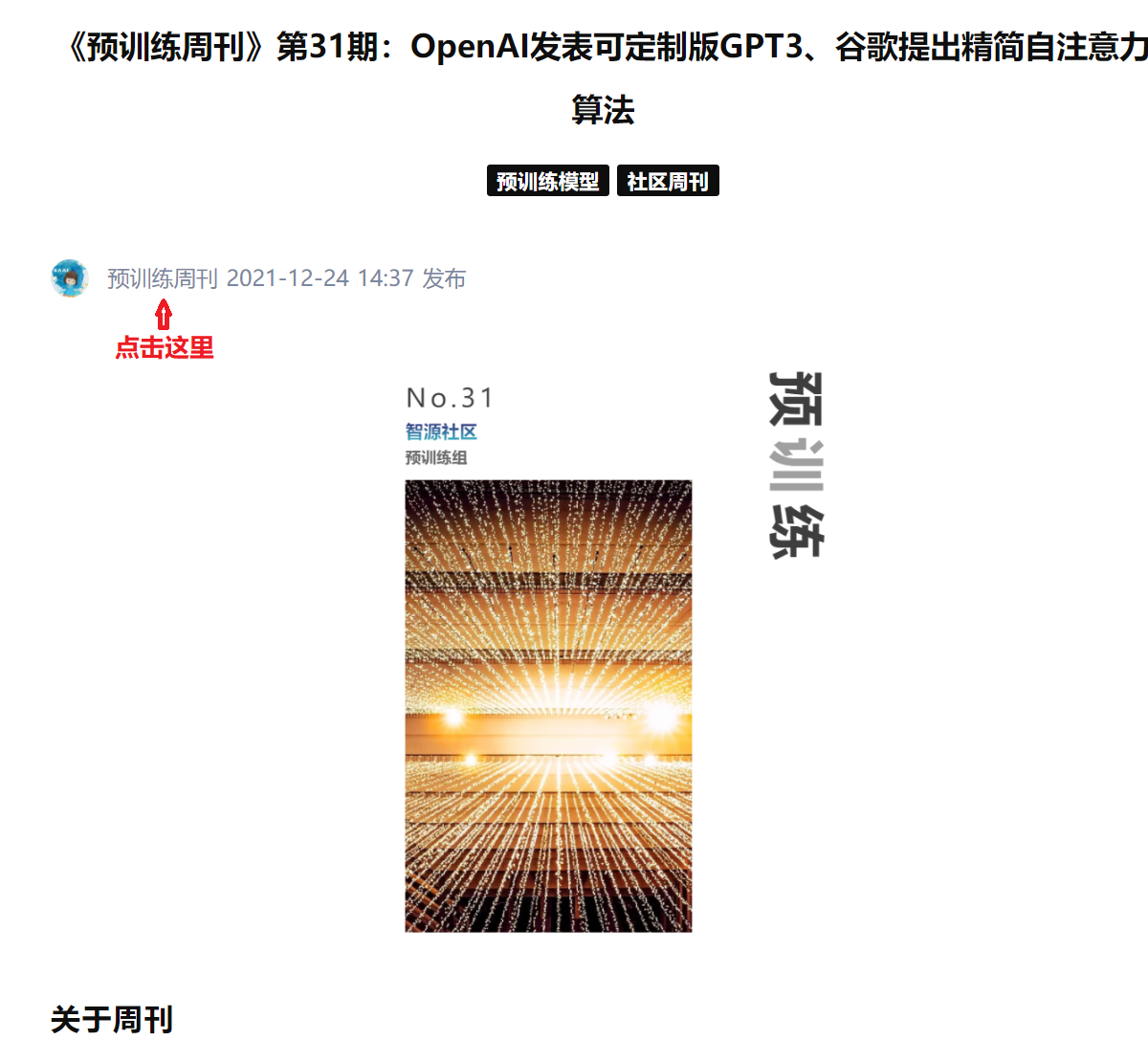
3,点击“关注TA”(如下图)
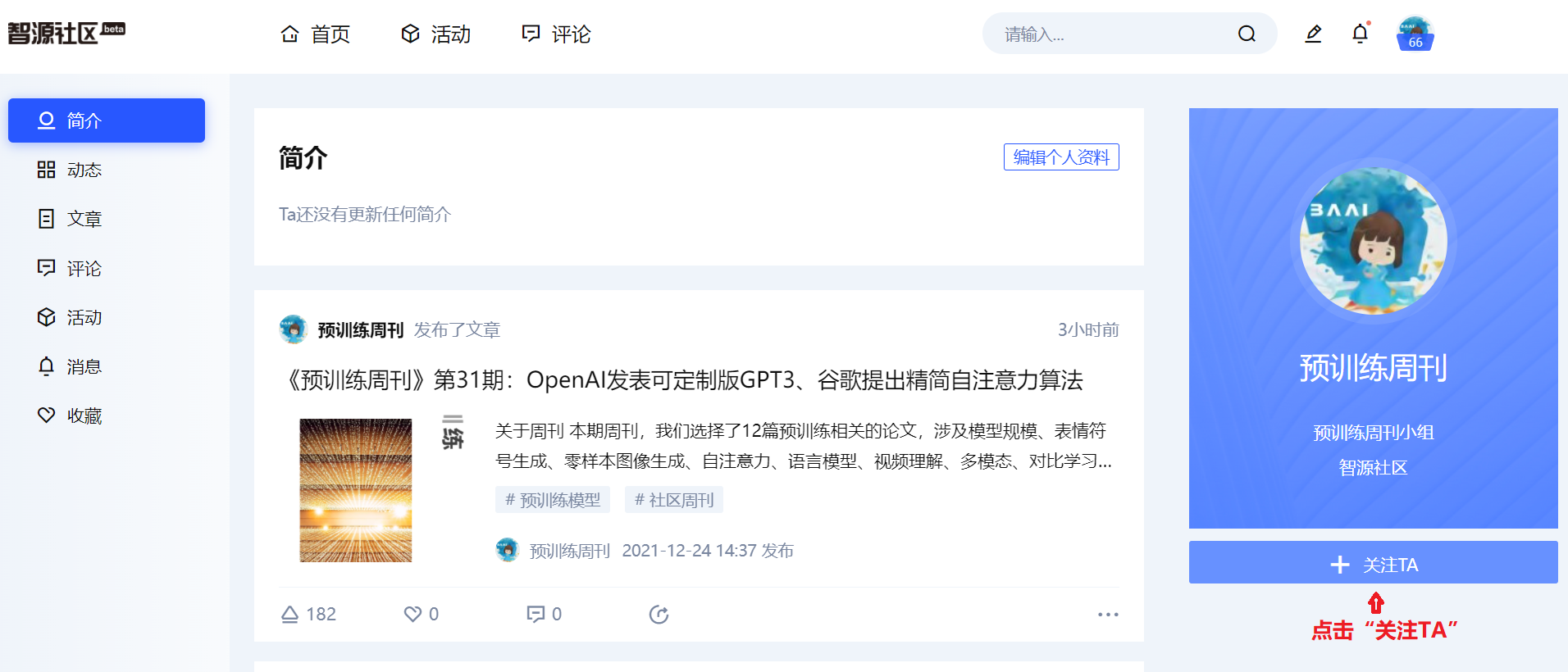
4,您已经完成《预训练周刊》订阅啦,以后智源社区自动向您推送最新版的《预训练周刊》!
论文推荐
标题:微软|GIT: A Generative Image-to-text Transformer for Vision and Language(GIT:生成式视觉和语言变换器)
作者:Jianfeng Wang, Zhengyuan Yang, Lijuan Wang等
简介:本文介绍了一种多模态建模方法。作者设计和训练了一个生成式图像到文本转换器 GIT,以统一视觉语言任务,如图像/视频字幕和问答。生成模型提供一致的网络架构预训练和微调,现有工作通常包含复杂的结构(单模/多模-编码器/解码器),并依赖于外部模块探测器/标记器和光学字符识别(OCR)。在GIT 中,作者简化架构为一个图像编码器和一个文本解码器,在一种语言下建模任务。作者还扩展了预训练数据和模型大小,以提高模型性能。作者的GIT斩获了新的最佳效果,在12个具有挑战性的基准上有很大的提升。例如,作者的模型在 TextCaps 上首次超越人类表现 (138.2与CIDEr中的125.5相比)。此外,在图像分类和场景文本识别标准基准测试,作者还提出了一种基于生成的新方案。
论文下载:https://arxiv.org/pdf/2205.14100v1.pdf
阅读详情
标题:北大、微软|On the Advance of Making Language Models Better Reasoners(关于使语言模型更好的推理的进展)
作者:Yifei Li, Zeqi Lin, Weizhu Chen等
简介:本文提出了一种语言模型推理的方法。大型语言模型,如 GPT-3、PaLM在少样本学习中表现出了卓越的表现。但是,它们仍然在推理任务中挣扎,例如算术基准测试GSM8K。最近在产生最终答案之前,有意识地指导语言生成推理步骤链的模型,成功地将GSM8K基准测试从问题解决率从17.9%提升至58.1%。在本文中,作者提出了一个新的方法,多样化(推理步骤多样化验证器),以进一步提高他们的推理能力。多样化的首次探索不同的提示,以增强多样性推理路径。其次多样化引入验证器来区分好的答案从糟糕的答案中选出更好的加权投票。最后,多样化验证每个步骤的正确性,而不是将所有步骤的正确性视为一个整体。作者使用code-davinci-002最新的语言模型进行广泛的实验,并证明DIVERSE可以在八个推理基准中的六个(例如,GSM8K74.4%→83.2%)上实现新的最先进的性能,优于具有540B参数的PaLM模型。
论文下载:https://arxiv.org/pdf/2206.02336v2.pdf
阅读详情
标题:360、清华|Zero and R2D2: A Large-scale Chinese Cross-modal Benchmark and A Vision-Language Framework(Zero和R2D2:一种大规模的中文跨模态基准测试和视觉语言框架)
作者:Chunyu Xie, Heng Ca, Xiangyang Ji, Yafeng Deng等
简介:大规模数据集上的视觉语言预训练 (VLP) 已显示出卓越性能在各种下游任务上的表现。完整且公平的基准(即包括大规模的预训练数据集和各种下游任务)对于VLP至关重要。然英语语料库有很多基准,但构建一个VLP与其他语言(如中文)的丰富基准测试仍然是一个关键问题。作者应用全局对比预排序分别学习图像和文本的单个表示形式。然后作者通过图像-文本交叉以细粒度的排序方式融合表示编码器和文本图像交叉编码器,进一步提升能力该模型,作者提出了一种由目标引导组成的双向蒸馏策略蒸馏和功能引导蒸馏,命名为R2D2。作者在四个公共跨模态数据集上和五个下游数据集实现了最先进的性能。在进行零样本任务时Flickr30k-CN、COCO-CN 和 MUGE、R2D2 在 2.5 亿个数据集上进行预训练,与最先进的技术相比,平均召回率分别提高了 4.7%、5.4% 和 6.3%。
代码下载:https://github.com/yuxie11/R2D2
论文下载:https://arxiv.org/pdf/2205.03860v3.pdf
阅读详情
标题:德国慕尼黑数字图书馆、奥地利维也纳大学等| hmBERT: Historical Multilingual Language Models for Named Entity Recognition
作者:Stefan Schweter, Luisa März, Katharina Schmid, 等
简介:本文研究跨语言NER结合预训练技术实现历史语言模型。与标准命名实体识别(NER)相比,在历史文本中识别“人、地点和组织”是一个巨大的挑战。为了获得机器可读的语料库,通常需要扫描历史文本并进行OCR光学字符识别。因此,导致历史语料库包含很多错误。此外,位置或组织等实体可能会随着时间的推移而发生变化,这带来了另一个挑战。总之,历史文本有几个与现代文本截然不同的特点,用于训练神经标记者的大型标记语料库在这一领域几乎不可用。在这项工作中,作者通过训练大型历史语言模型来解决历史德语、英语、法语、瑞典语和芬兰语的NER问题;通过使用未标记数据对语言模型进行预训练、来避免对标记数据的需要。本文提出的hmBERT是一种基于历史的多语言BERT语言模型。对于多语言经典评论粗粒度NER挑战,本文成果在三种语言中有两种语言的表现优于其他团队的模型。
论文下载:https://arxiv.org/pdf/2205.15575
阅读详情
标题:美国图森亚利桑那州大学、休斯顿卫理公会医院|Learning to segment with limited annotations: Self-supervised pretraining with regression and contrastive loss in MRI(使用有限注释学习分割:MRI中回归和对比丢失的自我监督预训练)
作者:Kanthashree Mysore Sathyendra, Thejaswi Muniyappa, Feng-Ju Chang,等
简介:本文研究利用预训练自监督技术减少手工标注的代价。获取用于深度学习(DL)模型监督训练的大型数据集的手工标注是一项挑战。与标记数据集相比,大型未标记数据集的可用性促使使用自我监督的预训练来初始化DL模型,以用于后续的分割任务。在这项工作中,作者考虑两种预训练方法来驱动DL模型学习不同的表示:a)利用图像内的空间依赖性的回归损失和b)利用图像对之间的语义相似性的对比损失。作者观察到,使用自我监督预训练的DL模型可以微调,以获得与标记数据集较少的可比性能。此外,作者还观察到,使用基于对比损失的预训练来初始化DL模型的效果优于回归损失。
论文下载:https://arxiv.org/pdf/2205.13109
阅读详情
标题:意大利摩德纳和雷吉奥埃米利亚大学、卡塔尼亚大学 | Transfer without Forgetting(迁移而不忘记)
作者:Matteo Boschini, Lorenzo Bonicelli, Angelo Porrello,等
简介:本文研究了连续学习(CL)和迁移学习(TL)之间的纠缠。特别是,作者阐明了网络预训练的广泛应用,强调了它本身会受到灾难性遗忘的影响。不幸的是,这一问题导致在以后的任务中对知识转移的利用不足。在此基础上,作者提出了无遗忘迁移(TwF),这是一种基于固定预训练双网络的混合连续迁移学习方法,它通过分层损失项不断传播源域中固有的知识。作者的实验表明:TwF在各种设置下都稳步优于其他CL方法、在各种数据集和不同缓冲区大小的情况下精度平均提高4.81%。
论文下载:https://arxiv.org/pdf/2206.00388
阅读详情
标题:港大、英伟达 | Factuality Enhanced Language Models for Open-Ended Text Generation(用于开放式文本生成的事实性增强语言模型)
作者:Nayeon Lee , Wei Ping , Peng Xu , Mostofa Patwary ,等
简介:本文研究提高大规模预训练语言模型 (LM) 文本生成事实的准确性。作者设计了 FactualityPrompts 测试集和指标来衡量 LMs的真实性。在此基础上,作者研究了参数大小从 126M 到 530B 的 LMs 的事实准确性。有趣的是,作者发现较大的 LM 比较小的LM更符合事实,尽管之前的一项研究表明,较大的 LM 存在误解可能不太真实。此外,开放式文本生成中流行的采样算法(如top-p)可能会由于在每个采样步骤中引入的“均匀随机性”而损害事实性。作者提出了事实核采样算法,该算法动态地适应随机性以提高生成的真实性,同时保持质量。此外,作者分析了标准训练方法在从事实文本语料库(如维基百科)中学习实体之间的正确关联方面的低效率。作者提出了一种事实性增强训练方法,该方法使用 TopicPrefix 更好地了解事实和句子完成作为训练目标,可以大大减少事实错误。
论文下载:https://arxiv.org/pdf/2206.04624.pdf
阅读详情
标题:德国乌尔姆大学 | Contrastive Representation Learning for 3D Protein Structures(3D蛋白结构的对比表征学习)
作者:Pedro Hermosilla, Timo Ropinski
简介:本文研究了蛋白质结构对比学习预训练。从三维蛋白质结构中学习已经在蛋白质建模和结构生物信息学中获得了广泛的关注。不幸的是,可用的结构数量比计算机视觉和机器学习中常用的训练数据量要低几个数量级。此外,当只考虑有注释的蛋白质结构时,这一数量甚至进一步减少,使得现有模型的训练变得困难,容易出现过度拟合。为了应对这一挑战,本文为三维蛋白质结构引入了一个新的表征学习框架,使用无监督的对比学习来学习蛋白质结构的有意义的表征,利用蛋白质数据库中的蛋白质。本文展示了这些表征如何被用来解决大量的任务,如蛋白质功能预测、蛋白质折叠分类、结构相似性预测和蛋白质-配体结合亲和力预测。此外,本文还展示了用预训练及微调网络如何使得任务性能的显著提高,在许多下游任务中取得新的最先进的结果。
论文下载:https://arxiv.org/pdf/2205.15675v1.pdf
阅读详情
标题:微软、芝加哥大学等 | Masked inverse folding with sequence transfer for protein representation learning(遮蔽反折叠与序列迁移的蛋白质表征学习)
作者:Kevin K. Yang, Niccolò Zanichelli, Hugh Yeh
简介:本文研究了序列和结构信息融合的预训练模型。对蛋白质序列进行自监督的预训练,使蛋白质功能和适应度预测的性能达到了一流水平。然而,仅有序列的方法忽略了实验和预测的蛋白质结构中所包含的丰富信息。同时,反折叠方法根据蛋白质的结构重建了蛋白质的氨基酸序列,但没有充分利用序列信息和对应结构信息。在这项研究中,作者训练了一个被遮蔽的反折叠蛋白质语言模型,其参数为一个结构图神经网络。本文表明,使用预训练的序列蛋白质遮蔽语言模型的输出作为逆折叠模型的输入,可以进一步提高预训练的复杂度。本文在下游的蛋白质工程任务中评估了这两个模型,并分析了来自实验或预测结构的信息对性能的影响。
论文下载:https://doi.org/10.1101/2022.05.25.493516
阅读详情
标题:约翰霍普金斯、加州伯克利等 | Towards generalizable prediction of antibody thermostability using machine learning on sequence and structure features(利用序列和结构特征的机器学习实现抗体热稳定性的泛化预测)
作者:Jeffrey J. Gray, Kathy Y. Wei等
简介:本文研究了预训练和简单CNN在抗体热稳定性预测的应用。作者分析了两种机器学习方法,一种是用预训练的语言模型捕捉序列突变的功能效应;另一种是用Rosetta能量特征训练的监督式卷积神经网络,以更好地从序列中对热稳定抗体单链可变区(scFv)变体分类。这两个模型都是通过来自多个scFv序列库的温度数据来训练的。本文表明,用能量特征训练的简单CNN模型比预训练的语言模型在分布外序列上的泛化性更好。此外本文证明,对于一个独立的具有20个热稳定实验结果的的单抗,这些在TS50数据上训练的模型可以识别18个残基位置和5个相同的氨基酸突变,显示出显著的泛化能力。本文的结果表明,这两类模型可以广泛适用于改善抗体的生物学特性,这类模型在优化单抗或多特异性生物制剂的大规模生产和传递方面有潜在的应用。
论文下载:https://doi.org/10.1101/2022.06.03.494724
阅读详情
标题:牛津、哈佛 | Tranception: protein fitness prediction with autoregressive transformers and inference-time retrieval(Tranception:用自回归Transformer和推理时间检索进行蛋白质适应度预测)
作者:Debora S. Marks, Yarin Gal等
简介:本文来自ICML2022,展示了一种新Transformer方法与其在适应度景观预测的应用。准确模拟蛋白质序列的适应度景观的能力对于从量化人类突变对疾病可能性的影响,到预测病毒中的免疫逃逸突变和设计新型生物治疗蛋白的广泛的应用至关重。在来自不同家族的大量未比对的蛋白质序列上训练的大型语言模型可以解决这些问题,并显示出最终弥补性能差距的潜力。本文提出了Tranception:一种新型的Transformer架构,利用自回归预测和推理时同源序列的检索来实现最先进的适应度预测性能。鉴于其在多个突变体上的明显更高的性能,对浅层比对的鲁棒性和对缩略词的评分能力,本文的方法提供了比现有方法更重要的范围。同时本文开发了ProteinGym,一套广泛的突变体效应的多重检测方法,与现有的基准相比,大大增加了检测方法的数量和多样性。
论文下载:https://arxiv.org/pdf/2205.13760v1.pdf
阅读详情
研究动态
标题:美国亚利桑那州立大学 | Neural Retriever and Go Beyond: A Thesis Proposal(神经信息检索及超越:一个理论建议)
作者: Man Luo
简介:本文研究信息检索器(IR)利用预训练方法的新思路提案。IR旨在大规模查找给定查询的相关文档(例如片段、段落和文章)。IR在许多任务中发挥着重要作用,例如需要外部知识的开放领域问答和对话系统。过去,基于词匹配的搜索算法得到了广泛的应用。近年来基于神经的算法(称为神经检索器)受到了越来越多的关注,它可以缓解传统方法的局限性。尽管神经检索器取得了成功,但它们仍然面临许多挑战,例如:需要少量的训练数据,无法回答简单的以实体为中心的问题。此外,现有的大多数神经检索器都是为纯文本查询而开发的。这会阻止它们处理多模态查询(即查询由文本描述和图像组成)。本论文提案有两个目标:首先,作者从三个角度介绍了解决神经检索器上述问题的方法,即新的模型结构、面向IR的预训练任务和生成大规模训练数据;其次,明确了未来的研究方向、并提出了相应的解决方案。
论文下载:https://arxiv.org/pdf/2205.16005
阅读详情
标题:斯坦福博士提出超快省显存Attention,GPT-2训练速度提升3.5倍,BERT速度创纪录
简介:最近,一个超快且省内存的注意力算法FlashAttention火了。通过感知显存读取/写入,FlashAttention的运行速度比PyTorch标准Attention快了2-4倍,所需内存也仅是其5%-20%。研究者认为,应该让注意力算法具有IO感知,即考虑显存级间的读写,比如大但慢的HBM(High Bandwidth Memory)技术与小但快的SRAM。基于这样的背景,研究人员提出了FlashAttention,具体有两种加速技术:按块递增计算即平铺、并在后向传递中重新计算注意力,将所有注意力操作融合到CUDA内核中。研究人员评估了用它训练Transformer的影响,包括训练时间、模型准确性,以及注意力运行时间和内存效率等,训练BERT速度相较于MLPerf训练记录提升15%,训练GPT-2的速度提高3.5倍,训练Transformer的速度比现有基线快。
阅读详情
标题:送给大模型的「高考」卷:442人联名论文给大模型提出204个任务,谷歌领衔
简介:随着规模的不断扩大,语言模型展示了定量改进和新的定性能力。尽管它们具有潜在的变革性影响,但其表现出的新功能特征仍然很差。为了给未来的研究提供更多信息,为颠覆性的新模型能力做好准备,了解语言模型当前和近期的能力和局限性至关重要。为了应对这一挑战,谷歌提出了超越模仿游戏基准(Beyond the Imitation Game Benchmark,BIG-bench)。
BIG-bench 目前由 204 个任务组成,获得了来自 132 个研究机构的 442 位作者贡献。该基准的任务主题多种多样,涉及语言学、儿童发展、数学、常识推理、生物学、物理学、社会偏见、软件开发等领域的问题。
阅读详情
标题:OpenAI|训练大模型的技术
简介:大型神经网络是人工智能许多最新进展的核心,但训练它们是一项艰巨的工程和研究挑战,需要编排一个GPU集群来执行单个同步计算。随着集群和模型规模的增长,机器学习从业者已经开发出越来越多的技术来并行化许多 GPU 上的模型训练。乍一看,理解这些并行技术似乎令人生畏,但是只需对计算结构进行一些假设,这些技术就会变得更加清晰 。 在这一点上,只是像网络交换机在数据包周围穿梭一样,从A到B的比特。
阅读详情
标题:腾讯&上交&浙大将最火的CLIP推进到PyramidCLIP和Zero-shot
简介:大规模视觉语言预训练在下游任务中取得了可喜的成果。现有的方法高度依赖于这样一个假设,即从互联网上抓取的图像-文本对是完全一对一对应的。然而,在实际场景中,这一假设很难成立:通过对图像的关联元数据进行爬取获得的文本描述通常存在语义不匹配和相互兼容性问题。为了解决这些问题,作者引入了金字塔CLIP(PyramidCLIP),它构建了一个具有不同语义层次的输入金字塔,并通过层次内语义对齐和跨层次关系对齐以层次的形式对齐视觉元素和语言元素。此外,作者还通过soften负样本(未配对样本)的损失来调整目标函数,以削弱预训练阶段的严格约束,从而降低模型过度约束的风险。在三个下游任务上的实验,包括zero-shot图像分类、zero-shot图像文本检索和图像目标检测,验证了所提出的金字塔CLIP的有效性。特别是,在1500万图像-文本对的预训练数据量相同的情况下,基于ResNet-50/ViT-B32/ViT-B16的PyramidCLIP在ImageNet上的Zero-Shot分类top-1精度,比CLIP分别高出19.2%/18.5%/19.6%。
阅读详情
欢迎加入预训练社群
如果你正在从事或关注预训练学习研究、实现与应用,欢迎加入“智源社区-预训练-交流群”。在这里,你可以:
-
学习前沿知识、求解疑难困惑
-
分享经验心得、展示风貌才华
-
参与专属活动、结识研究伙伴
请扫描下方二维码加入预训练群(备注:“姓名+单位+预训练”才会验证进群哦)

内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢